Matrox Parhelia 128MB
Результаты тестов
2D-графика
Традиционно начнем с 2D. Ну, как говорится, Matrox есть Matrox. Тут все на высшем уровне, 1600х1200х100Гц на обеих "головах" выглядят безупречно. Никаких замечаний!
Я даже не стану повторять традиционную фразу о том, что оценка 2D-качества есть вещь субъективная. Подобные платы выпускает только компания Matrox, поэтому, полагаю, что в данном случае качество уже не зависит от конкретного экземпляра, но связка карта-монитор могут по-прежнему играть огромную роль, прежде всего качество монитора и кабеля.
Полагаю, что скорость работы Parhelia в 2D также не нуждается в измерениях, как и у всех карт последнего поколения, она высока.
3D-графика, MS DirectX 8.1 SDK — предельные тесты
Для тестирования различных предельных характеристик чипов мы использовали модифицированные (для большего удобства и контроля) примеры из последней версии DirectX SDK (8.1, релиз). Без лишних преамбул перейдем к уже хорошо знакомым нашим постоянным читателям тестам:
Optimized Mesh
Этот тест призван выяснить практический предел пропускной способности ускорителя по треугольникам. Для этого используется несколько одновременно выводимых в небольшом окне моделей, каждая из которых состоит из 50 тысяч треугольников. Текстурирование отсутствует. Размеры моделей минимальны — каждый треугольник не превышает одного пиксела. Хочется сразу отметить, что результат этого теста, разумеется, останется недостижим для реальных приложений, где размеры треугольников значительны, присутствуют текстуры и освещение. Приведем результаты этого теста для трех методов отрисовки — оптимизированной для оптимальной скорости вывода (в том числе, с учетом размера внутреннего кэша вершин на чипе) модели — Optimized, неоптимизированной исходной модели — Unoptimized и той-же неоптимизированной модели, выводимой в виде одного Triangle Strip — Strip:
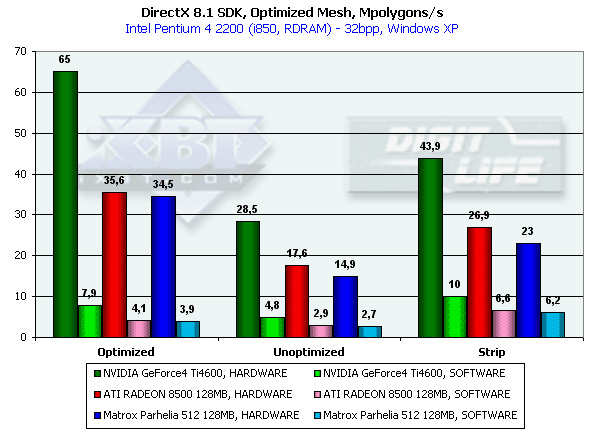
В случае полностью оптимизированной модели, когда влияние подсистемы памяти минимально, мы измеряем практически чистую производительность трансформации и установки треугольников. Налицо безоговорочное лидерство Ti 4600. 65 миллионов треугольников в секунду — цифра нешуточная, практически вдвое превосходит результаты RADEON 8500 и Parhelia. Мы понимаем, что именно так и должен был отразиться на производительности Ti 4600 второй блок T&L относительно RADEON 8500, но почему Parhelia с ее 4-мя блоками вершинных шейдеров так отстала? Налицо работа только одного конвейера.
Кроме того, отметим существенное преимущество всех GPU в случае принудительной активации программного расчета геометрии. В случае Strip модели это преимущество нивелируется из-за существенного (вдвое) снижения объема передаваемых данных.
Производительность блока вершинного шейдера
Этот тест позволяет определить предельную производительность блока вершинных шейдеров. Выполняется достаточно сложный шейдер, вычисляющий как видовые преобразования, так и геометрические функции. Тест проводится в минимальном разрешении, дабы минимизировать влияние закраски:
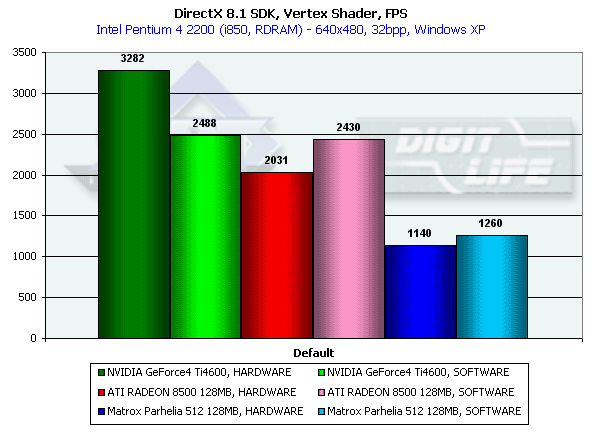
И вновь налицо существенное преимущество реально "двойного" T&L Ti 4600. И снова сильный проигрыш Matrox Parhelia.
Интересно, что со времени прошлого большого обзора NV25 скорость выполнения RADEON 8500 вершинных шейдеров почти не выросла, но увеличение процессорной мощности тестового стенда позволила программной эмуляции опередить по скорости аппаратную обработку. Что наблюдается также и у Matrox. Вероятно, что и карта от ATI и от Matrox уперлись в частоты работы своих GPU, и 2.2ГГц процессор Pentium 4 справляется с этой задачей даже быстрее.
Вершинный матричный блендинг
Эта возможность T&L используется для правдоподобной анимации и скиннинга моделей. Мы протестировали блендинг с использованием двух матриц как в жестком "аппаратном" варианте, так и с использованием вершинного шейдера, выполняющего ту же функцию. Кроме того, мы, как обычно, "подстраховались" результатами, полученными в режиме програмной эмуляции T&L:
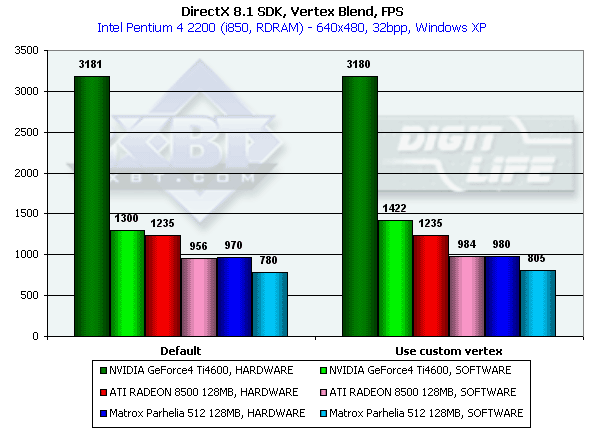
На сей раз, программная эмуляция везде проигрывает аппаратному исполнению, упираясь, судя по всему, (обратите внимание на похожести результатов с шейдером и без) в скорость передачи геометрии по AGP. В случае аппаратного исполнения, мы снова видим всплеск у Ti 4600 из-за его 2-х конвейеров вершинных шейдеров, и незначительный рост у RADEON 8500 и Parhelia. Интересно, что жесткий аппаратный блендинг на RADEON 8500 равен, а на Parhelia чуть медленнее шейдерного, но отличия крайне малы.
EMBM рельеф
В этом тесте мы измеряем производительность, а точнее ее падение, возникающее при использовании наложения карт отражения (Environment) и рельефа на основе карт отражения (EMBM — Environment Bump). Для тестирования использовалось разрешение 1280*1024 — т.к. именно в нем различия между картами и разными режимами текстурирования выражены наиболее резко:
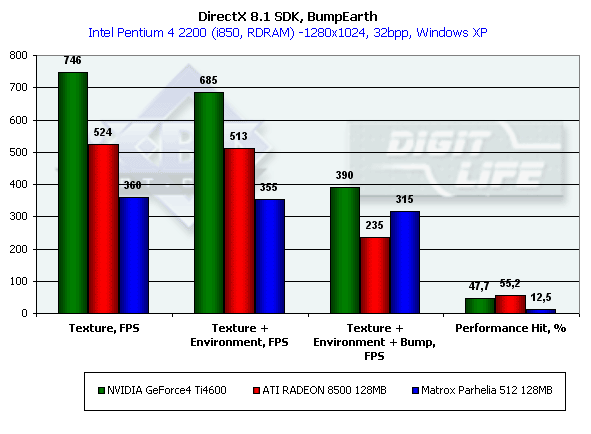
Ti 4600 вновь занимает четкую лидирующую позицию, заметно опережая остальные карты по эффективной скорости закраски во всех трех режимах. Сильнее всего EMBM бьет по R200, однако сама по себе разница в падении не столь существенна, сколь низка эффективность любой (даже без EMBM) закраски на R200. Чип от Matrox красит хотя и медленнее, но при полной нагрузке гораздо эффективнее, чем R200.
Производительность пиксельных шейдеров
Мы вновь использовали модифицированный пример MFCPixelShader, измерив производительность карт в высоком разрешении при выполнении 5 различных по сложности шейдеров, для билинейно фильтрованных текстур:

Ti 4600 на коне, и характер зависимости от сложности шейдера и числа текстур представляет собой почти стабильную горизонталь с некоторым падением вначале. То же самое можем сказать и про Parhelia. Как мы видим, наличие одного числа пиксельных конвейеров у Ti 4600 и у Parhelia с разницей лишь в частотах и обусловили почти постоянную дельту между этими двумя картами. А вот R200 демонстрирует печальную слабость, существенно сдавая на сложных заданиях. Повторное использование текстурных блоков стоит ему гораздо дороже, нежели творениям Matrox и NVIDIA.
Итак, подведем первый промежуточный итог. По сумме тестов DX 8.1 SDK карта Matrox Parhelia 128MB выходит почти пораженцем. Этого от нее не ожидалось — ведь декларации гласили о наличии 4-х вершинных конвейеров, а в действительности задействован только один. Это может быть следствием как несовершенства драйверов, так и наличия ошибки в чипе. А вот работа с пиксельными шейдерами у Parhelia на высоте. Хотя и отстает по скорости от Ti 4600.
Мы еще вернемся к этим тестам несколько позже (примерно в августе), когда будет возможность протестировать наличие VS 2.0 на DirectX 9.0.
3D-графика, 3DMark2001 SE — синтетические тесты
Подчеркну, что все замеры по всем 3D-тестам проводились в 32-битной глубине цвета.
Скорость закраски
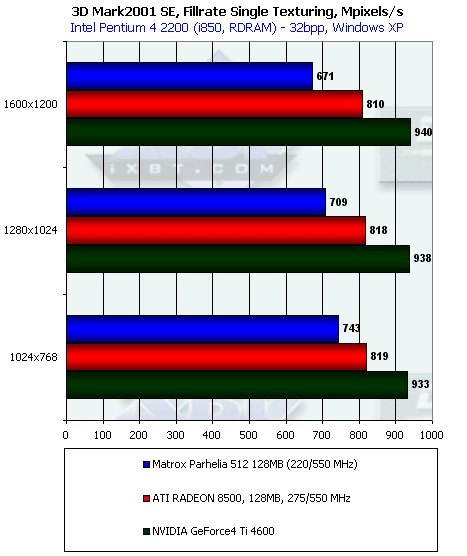
Напомним, что теоретические пределы для данного теста составляют 880 миллионов пикселей в секунду для Parhelia, 1100 для RADEON 8500 и 1200 для Ti 4600 соответственно. Как мы видим, по фактической скорости закраски Parhelia наиболее близко подошла к пиковым значениям.
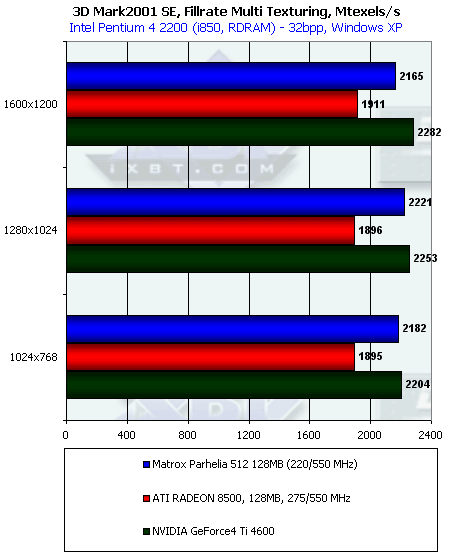
Также напомним, что пиковые значения для этого теста составляют 3520 (1760) миллионов текселей в секунду для Parhelia (в скобках указано значение при работе схемы 4 конвейера по 2 текстурника на каждом), 2200 — для RADEON 8500 и 2400 для Ti 4600. И уже тут хорошо видно, что прямо около своей пиковой скорости оказался уже Ti 4600, чуть далее — RADEON 8500. А вот с Parhelia все более сложно. Очевидно, что была задействована схема не 4 х 2, а 4 х 4, однако при этом реальная скорость закраски оказалась сильно ниже пикового значения. И это еще одно доказательство того, что чип работает не в полную свою силу. Почему? Лучше спросить у инженеров из Matrox (или программистов).
Сцена с большим количеством полигонов
На этом тесте особое внимание следует уделить минимальному разрешению — именно там зависимость от закраски практически нивелируется:
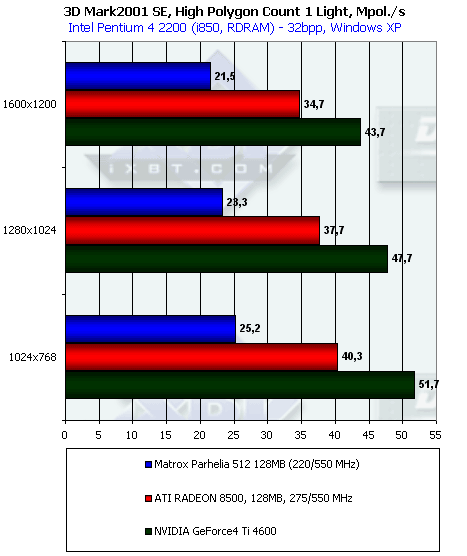
При наличии одного источника света Ti 4600 показывает себя абсолютным лидером. Его результат не только значительно (более, чем в 2 раза) превосходит Parhelia, но и (что более важно) вплотную приблизился к значению практического предела пропускной способности по треугольникам, полученному ранее с помощью Optimized Mesh из DX8.1 SDK. Еще одно свидетельство мощи двойного T&L Ti 4600. Впрочем, не будем умалять достоинств RADEON 8500, также приблизившегося к предельной цифре, полученной в тесте из SDK. А вот с Parhelia снова неясно. Налицо отставание скорости работы с одним источником света от продемонстрированного ею же предела ПС по полигонам. Опять драйверы?
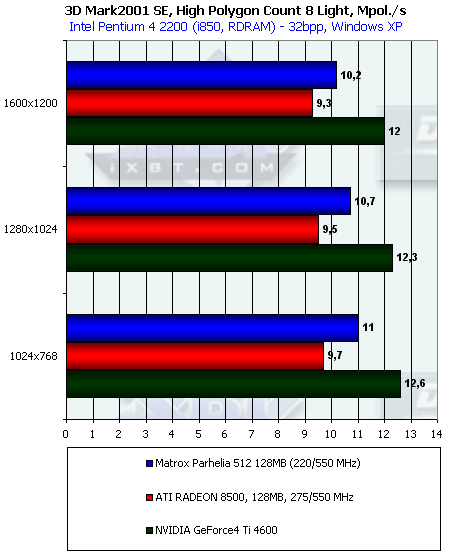
А вот в случае 8 источников света Parhelia несколько реабилитирует себя: с ростом числа источников его производительность падает более медленно, чем RADEON 8500, да и в целом продукт от Matrox тут сильно выигрывает у R200. Но лидер — по-прежнему Ti 4600.
Рельефное текстурирование
Посмотрим на результаты синтетической EMBM сцены:
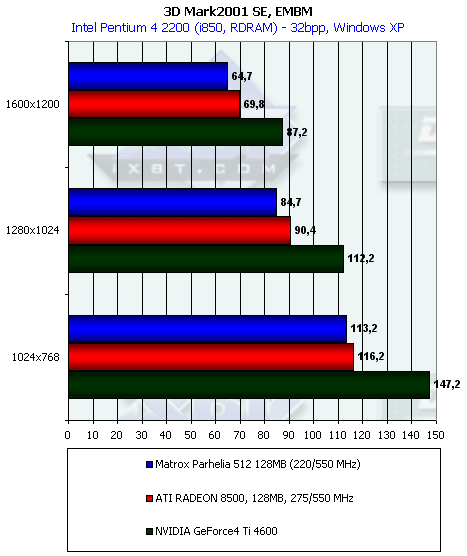
Несмотря на то, что в предельных тестах Parhelia продемонстрировала бОльшую скорость работы с рельефным текстурированием, чем у RADEON 8500, в данном случае видно небольшое отставание от последнего. А теперь DP3 рельеф:
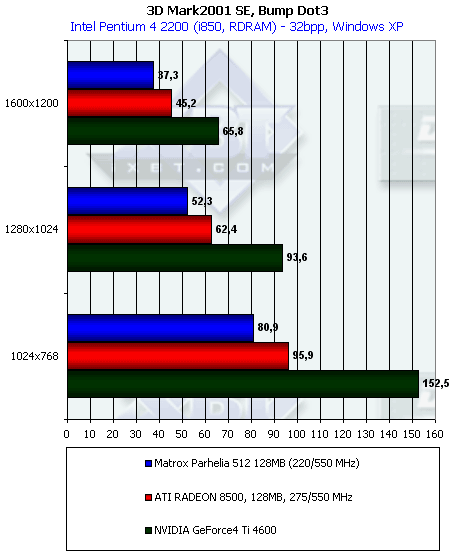
Картина схожая.
Вершинные шейдеры
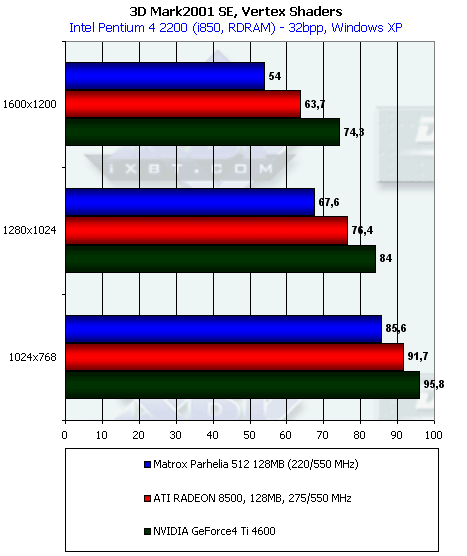
Данный тест лишь подтвердил работоспособность только одного конвейера T&L у Parhelia, поскольку мы наблюдаем отставание этой карты от RADEON 8500 в точном соответствии с частотами. Кстати, обратим внимание на то, что с ростом разрешения и RADEON 8500, и Parhelia стремительно сдают свои позиции, упираясь в недостаточную эффективность закраски, в то время как скорость Ti 4600 падает медленнее.
Пиксельный шейдер
Руководствуясь высказанными выше соображениями о том, что слишком малые разрешения "упираются" в геометрию, а слишком большие — в пропускную полосу памяти, обратим основное внимание на 1024х768 и 1280х1024:
Чудеса, да? Совсем недавно при тестировании пиксельных шейдеров в SDK Parhelia демонстрировала явный перевес над RADEON 8500. А тут мы видим просто провальные результаты. Учитывая приспосабливаемость теста 3DMark2001 SE к разным картам, могу предположить, что вскоре выйдет патч к нему, после которого скорость работы Parhelia резко возрастет. Для чистоты эксперимента посмотрим и на тест Advanced Pixel Shader.
Картина очень похожая. Заметим, что в данном случае карты от Matrox и NVIDIA исполняют задачу за 2 прохода, используя шейдеры версии 1.1, RADEON 8500 требуется только 1 проход с использованием шейдеров 1.4, но это его не спасает.
Спрайты

В этой области у Parhelia совсем все плохо.
Итак, подведем первый промежуточный итог. По сумме синтетических тестов карта Matrox Parhelia 128MB
проигрывает своим конкурентам (не считая работы с большим числом источников света).
Впрочем, частично это и ожидалось — ведь частота работы карты сильно ниже, чем у соперников, несмотря
на наличие вдвое большего числа текстурников. Да и 4 вершинных конвейера не видать. Так что, ждем
улучшений работы с выходом новых версий драйверов (если это виноваты драйверы) или смены заявленных характеристик
от Matrox (если виноват сам чип и это уже не исправить программным путем).
Однако не будем забывать, что только результаты
реальных приложений позволят нам судить об общей производительности, да и сбалансированности Parhelia.
Оставайтесь с нами.
| 8 июля 2002 г. |
|
|