Обзор «интеллектуальной системы оптического распознавания» - ABBYY FineReader 8 Professional Edition
- Назначение продукта и установка
- Для тех, кто ранее не работал с FineReader
- Интерфейс
- ABBYY Screenshot Reader
- Выводы
Назначение продукта и установка
Программные приложения оптического распознавания данных часто обозначают просто - «OCR». Расшифровывается эта аббревиатура как Optical Character Recognition. Данные могут быть любого рода: книга, газета, журнал, факс - любой документ, содержащий текст, который надо перенести в компьютер.
Имея на руках документ и необходимость перевести его в электронную форму, у пользователя есть выбор: перепечатать документ, восстановив его первоначальное оформление (таблицы, колонки, иллюстрации и так далее) или использовать сканер и OCR-приложение, что гораздо быстрее и проще, в случае если OCR-приложение распознает документ с достаточной точностью.
Знакомство с программой FineReader компании ABBYY у меня началось ещё в 1995 году. Тогда компания ABBYY называлась более благозвучно, на мой взгляд, «BIT Software», а OCR-приложение имело порядковый номер 2.0. Версии 1.0 ни один из известных мне людей не видел, хотя, это совершенно не важно, ибо те же Windows реально начали использовать только начиная с версии 3.0.
Хотел бы отметить сразу, что официальное название программы - ABBYY FineReader 1.0/2.0/3.0 и так далее. Но, да простят меня сотрудники ABBYY, каждый раз название компании мы указывать не будем, потому, как и так ясно о чём идёт речь.
«Двойка» в том далёком уже 1995 году умещалась на пяти дискетах, и требовала целых 10 мегабайт на жестком диске.
В то время планшетный сканер был далеко не у всех, люди пользовались ручными сканерами. Сканирование длилось неимоверно долго, а дальнейшая «склейка» изображения (ручной сканер едва захватывал половину листа А4) не всегда давала корректный результат. Тем не менее, сканирование уже тогда позволяло значительно сократить время, требуемое на оцифровку текста, и, разумеется, чем введенное оцифрованное изображение распознавать было также важно.
Реальных конкурентов у FineReader тогда, впрочем, как и сейчас, не было. Да, был Presto! OCR 3.0, был CuneiForm, актуальной на тот момент версии 2.95 с дистрибутивом всего в 4,3 МБ от российского разработчика Cognitive Technologies. Но всё это были разработки с менее удобным интерфейсом, с несколько меньшей точностью распознавания, а Presto!, как продукт западной разработки, либо вовсе не работал с русским языком, либо результаты распознавания приходилось долго и усиленно править. Правда, стоит отметить, что CuneiForm приемлемо работал на медленных компьютерах, тогда как у FineReader с этим были некоторые трудности.
FineReader 3.0 Professional, вышедший в 1996 году на тот момент был уже весьма серьезным, законченным продуктом. Список протестированных и поддерживаемых сканеров демонстрировал 28 моделей, среди них были и аппараты Hewlett-Packard, для работы с которыми использовалась собственные разработки HP, что накладывало определённые трудности в работе для большинства программ распознавания. Программа уже умела использовать MMX-инструкции, и процесс распознавания на быстрых компьютерах был значительно ускорен. Дистрибутив OCR-приложения при этом можно было приобрести на дискетах, количество которых варьировалось от девяти до одиннадцати, в зависимости от версии программы.
 Разработчики Cognitive Technologies тоже не сидели сложа руки, и версия CuneiForm 97 v4.0 стала достойной альтернативой FineReader. Языки распознавания можно было подключать отдельно, а интерфейс был в некоторых случаях более продуманным и удобным, чем у продукта BIT Software. Также новую версию CuneiForm выгодно отличала цена (но много ли в то время людей покупали лицензионные продукты?) и более эффективное использование оперативной памяти компьютера.
Разработчики Cognitive Technologies тоже не сидели сложа руки, и версия CuneiForm 97 v4.0 стала достойной альтернативой FineReader. Языки распознавания можно было подключать отдельно, а интерфейс был в некоторых случаях более продуманным и удобным, чем у продукта BIT Software. Также новую версию CuneiForm выгодно отличала цена (но много ли в то время людей покупали лицензионные продукты?) и более эффективное использование оперативной памяти компьютера.
Чаша весов заметно качнулась в сторону FineReader с выходом в начале 98-го года FineReader 4.0. Новая версия появилась как раз тогда, когда неплохой планшетный сканер уже стало возможно купить за 150 долл. «Четверка» стала одной из наиболее распространённых программ распознавания данных на компьютерах пользователей, ко всему прочему она стабильно работала под Windows NT 4.0, правда, это накладывало  необходимость устанавливать Service Pack 3 в обязательном порядке. Поэтому дистрибутив на диске занимал целых 320 мегабайт, но если покопаться, то можно было обнаружить, что 295 из них занимал SP3 для различных языков.
необходимость устанавливать Service Pack 3 в обязательном порядке. Поэтому дистрибутив на диске занимал целых 320 мегабайт, но если покопаться, то можно было обнаружить, что 295 из них занимал SP3 для различных языков.
Комментарий специалиста ABBYY: в четвёртой версии введена процедура повторной обработки неуверенно распознанных или нераспознанных слов. Завершив анализ страницы, система вновь обращалась к тем объектам, которые не удалось уверенно распознать при первом проходе. К этому моменту классификаторы успевали обучиться на материале всей страницы, и получали возможность распознать то, что «не далось» вначале.
Четвертая версия FineReader запомнилась также обилием обновлений. Наиболее ходовыми стали версии 4.64 и 4.72. У многих, в том числе и у меня, 4.72 «жила» на компьютере дольше остальных. На фоне этого выход CuneiForm 99 OCR v5.00 прошел практически незаметно. Во всяком случае, пользователей, работавших с новым продуктом Cognitive Technologies, было в разы меньше.
Заметным шагом в сторону «не продвинутых» пользователей был сделан в пятой версии программы. Мастер сканирования позволил полностью избавить от такой непонятной многим функции, как «сегментирование», интерфейс и навигация были максимально облегчены и упрощены. Это дало возможность FineReader 5.0 стать излюбленным инструментом многих пользователей, а все основы, заложенные в этой версии, использовались во всех дальнейших. Что же касается лично меня, то я оставил себе версию 4.72, так как не заметил ощутимой разницы в скорости распознавания, а вот упрощение интерфейса воспринял, как многие автомобилисты в своё время восприняли автоматическую коробку передач у автомобиля, выискивая множество аргументов в пользу механики.
FineReader 6.0 почему-то многим пользователям предыдущей версии не приглянулся, хотя, по большому счёту, заметных кардинальных внешних отличий от FineReader 5.0 в новой версии программы, ждать которой пришлось почти два года, по сути, не было. Основные изменения коснулись внутреннего устройства программы и непосвящённым пользователям были неочевидны. От раза к разу разработчики FineReader говорили об улучшении алгоритмов распознавания и о повышении, соответственно, скорости распознавания. Именно в шестой версии FineReader был наделён ещё двумя технологиями, получившими названия «адаптивной бинаризации» и «фильтрации текстур». Обе они были направлены на улучшение распознавания «проблемных» документов, где текст расположен на цветном фоне или же имеет яркостные дефекты, образовавшиеся при передаче по факсу или в силу других причин.
В предыдущих версиях FineReader необходимо было привести оцифровываемый документ в однобитный растровый формат, что несколько осложняло распознавание, когда необходимо было сосканировать документ с цветными фотографическими элементами, сохранив при этом первозданное форматирование. Применяемый в FineReader 6.0 механизм адаптивной бинаризации сам определял для каждого слова оптимальные параметры яркости и контрастности, с тем, чтобы после приведения к режиму Black & White/Lineart он стал как можно более четким. После этого вступал в дело алгоритм очистки, который был реализован еще в четвёртой версии, он анализировал содержимое документа и удалял из него мелкие точки, оставляя лишь большие заполненные массивы, которые предположительно могли оказаться символами.
Другим важным обновлением в FineReader 6.0 стала возможность работы с PDF-файлами, точнее, добавилась функция импорта из PDF, тогда как экспорт в PDF был реализован ещё в четвёртой версии. Теперь у пользователя появилась возможность не только распознавать данные, введённые с помощью сканера, но и файлы, которые, как правило, можно было лишь прочитать такими утилитами, как Adobe Acrobat. Это было весьма кстати, так как формат набрал заметную распространённость, а путей быстро перевести файл из формата PDF в тот же Microsoft Word почти не было. Люди часто просто распечатывали PDF-файлы, а потом сканировали распечатанное. Правда, разработчики ABBYY пошли тогда на хитрость, поддержка формата PDF была не «нативной». На самом деле FineReader 6.0 перед распознаванием с помощью бесплатной утилиты PDF2BMP преобразовывал файл в растровое однобитное изображение и далее работал как с сосканированными документами. Для корректной передачи многоязычных документов вместе с новой программой поставлялся набор шрифтов Type 1 нескольких основных типов с расширенной таблицей символов.
Была значительно усовершенствована и система предварительного редактирования распознанных страниц. Внутренний редактор теперь представлял собой не просто окно редактирования текста, а полноценное WYSIWYG-пространство, где отображался точный макет комплексного итогового документа (например, многоколоночный текст, отдельные текстовые блоки и так далее).
Изменился и интерфейс программы. Начиная с того, что пиктограммы стали более «мультяшно-полноцветными», как в системе Windows XP, заканчивая появившейся настраиваемой панелью инструментов, позволяющей вынести наиболее часто используемые функции и убрать ненужные.
Шестая версия два раза несколько перерабатывалась, судя по выпуску сервис-паков для программы.
 Очередная, седьмая версия FineReader, вышла в сентябре 2003 года совершенно тихо и не заметно. Как всегда было объявлено о совершенствовании алгоритмов и скорости распознавания, более качественной работе с PDF-файлами, увеличении числа языков распознавания, поддержке формата XML и тесной интеграции с Microsoft Office 2003. Заявлено о совершенствовании системы проверки орфографии, а также «очень актуальной» для многих пользователей поддержке распознавания штрих-кодов, в том числе двухмерных типа PDF-417.
Очередная, седьмая версия FineReader, вышла в сентябре 2003 года совершенно тихо и не заметно. Как всегда было объявлено о совершенствовании алгоритмов и скорости распознавания, более качественной работе с PDF-файлами, увеличении числа языков распознавания, поддержке формата XML и тесной интеграции с Microsoft Office 2003. Заявлено о совершенствовании системы проверки орфографии, а также «очень актуальной» для многих пользователей поддержке распознавания штрих-кодов, в том числе двухмерных типа PDF-417.
Ниже вы сможете сравнить интерфейсы FineReader 6-ой и 7-ой версий. Как можете заметить, отличий практически нет.
Возможно, конечно, мной были упущены некоторые ключевые моменты, но, скачав Try&Buy версию FineReader 7.0, изучив список добавлений и изменений, веских оснований для перехода на новую версию обнаружено не было. Кстати говоря, до седьмой версии можно обновить программу еще с версии 4.0 Standart или Professional.
А что CuneiForm? В апреле 2000 года была выпущена обновлённая версия CuneiForm 2000 R2, на этом развитие проекта остановилось. С одной стороны - это понятно, поддерживать достойную конкуренцию FineReader очень нелегко, с другой - очень жаль, что рынок лишился единственного реального конкурента компании ABBYY, а только конкуренция в большей степени влияет на развитие рынка и технологий.
В отсутствие конкуренции, компания ABBYY два года работала над следующей версией своего пакета, уже восьмой в ряде продуктов FineReader.
Что нового в FineReader 8.0 Professional Edition? Вот что говорит разработчик:
«Новая версия ABBYY FineReader 8.0 Professional Edition сочетает в себе непревзойдённую точность распознавания, простоту использования и широкий диапазон настроек. Повышено качество распознавания факсов и документов, отсканированных с низким разрешением, на новый уровень выведено распознавание изображений, полученных с помощью цифровой камеры. Новый быстрый режим распознавания позволяет в несколько раз ускорить обработку качественно отпечатанных документов. Реализовано автоматизированное выполнение типовых задач распознавания, в том числе и по собственным сценариям. Быстрее и точнее стало преобразование PDF-файлов, добавлена функция защиты PDF-файлов паролем. Теперь в комплект поставки системы входит утилита для распознавания скриншотов».
На сегодняшний день существует две версии ABBYY FineReader 8.0: Professional Edition и Corporate Edition. Последняя отличается от «профессиональной» тем, что предназначена для работы в корпоративной сети с возможностью совместной работы над распознаванием документов.
Повышенная точность распознавания включает в себя, помимо традиционного улучшения самого алгоритма распознавания, повышение точности распознавания «специализированных» текстов, а также распознавания цифровых фотографий.
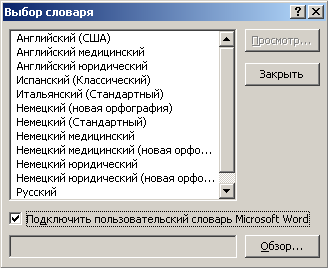
Повышение точности распознавания специализированных текстов обусловлено появившейся возможностью подключать при распознавании пользовательский словарь Microsoft Word, хотя, конечно, при его отсутствии преимущество этой функции будет неочевидно.
Распознавание изображений, снятых с помощью цифровой камеры, возможно, покажется невесть каким достижением, но, тем не менее, стоит учесть, что с точки зрения OCR-системы, цифровые фотографии значительно отличаются от отсканированных изображений. На снимках нередко встречаются искажения: неравномерное освещение, плохая фокусировка, «изогнутые» строки на краях документа, и т.д. Кроме того, в файлах цифровых фотографий зачастую отсутствует информация о разрешении.
Возможность распознавания цветных изображений, заложенная еще в шестой версии, уже тогда позволяла делать данную нехитрую операцию с высокой долей успеха. Достоинство FineReader 8.0 в том, что тот научился отличать сфотографированные документы от отсканированных и применять при этом для обработки снимков новую адаптивную технологию распознавания. Учитывая куда большую распространённость цифровых фотоаппаратов, нежели сканеров, данная функция может быть весьма полезной для многих пользователей.
Тем не менее, не стоит особо обольщаться. Действительно приемлемых результатов можно добиться на приличной камере уровня 4 Мпикс. Освещение при съёмке должно быть достаточным и ровным, а фотография - четкой, без «размыленностей» и заметного шума. Отснятые фотографии имеет смысл сохранять в формате TIFF, а не применять JPEG-сжатие, дабы не вносить дополнительных искажений. Для достижения гарантированного результата имеет смысл использовать при съёмке штатив. Выполнив все эти требования, можно будет без особых проблем передавать изображения даже в разрешении 1280х1024 и тратить минимум времени на дальнейшую корректировку после распознавания.
Дальнейшее развитие в FineReader 8 получила технология распознавания PDF-файлов. В новой версии усовершенствована технология обработки PDF-файлов. Как известно, некоторые PDF-файлы содержат так называемый текстовый слой, причём его содержимое может не полностью соответствовать видимому на экране документу. FineReader 8.0 предварительно анализирует содержимое файла и для каждого текстового блока принимает решение: распознать его или извлечь соответствующий текст из текстового слоя.
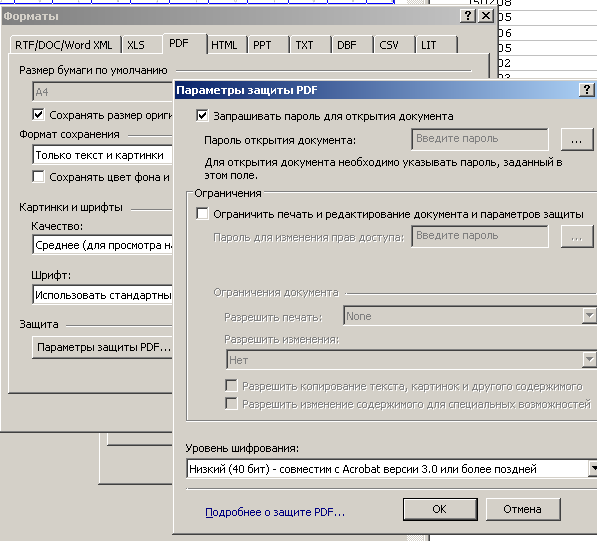
Также появилась возможность защиты PDF–файлов паролем. Пароль может быть установлен как на открытие файла, так и на прочие действия с документом (печать, извлечение содержимого, возможность редактирования, внесение комментариев, добавление/удаление страниц и др.). Предусмотрена возможность выбрать один из трёх уровней шифрования: 40-битный, 128-битный на основе стандарта RC4, 128-битный уровень, основанный на стандарте AES (Advanced Encryption Standard).
Добавлена возможность работы с дополнительной информацией PDF-файлов (заголовок, предмет, автор, ключевые слова). Эту информацию можно извлекать, редактировать или задавать заново по своему усмотрению
При преобразовании PDF-файла и сохранении результатов распознавания в форматы Microsoft Word, PDF и HTML FineReader 8.0 по умолчанию восстанавливает все гиперссылки, найденные в исходном документе. К таковым относятся как ссылки на внешние источники (интернет-сайты, другие файлы, и т.п.), так и внутренние ссылки, ведущие на другие страницы того же документа.
Одним из декларируемых моментов является то, что распознанные PDF-документы теперь можно сразу, без предварительного сохранения на диск, передавать в Adobe Acrobat. Реальной пользы от данной функции, кроме как предпросмотр распознаваемого документа с дальнейшим сохранением в PDF придумать сложно.
Теперь ABBYY FineReader 8.0 способен открывать графические файлы формата TIFF, сжатые по алгоритму LZW. Появилась возможность сохранять результаты распознавания в формат Microsoft Reader eBook (LIT), один из самых популярных форматов для создания электронных книг. При сохранении результатов распознавания в любом из форматов PDF, HTML, PPT, DOC, RTF, можно задавать цветность картинок – цветная, серая или чёрно-белая. Например, если в документе много цветных иллюстраций, может быть полезно сохранить некоторые из них как серые или чёрно-белые. Это существенно уменьшит размер получившегося файла.
Кроме того, появились дополнительные опции сохранения картинок при экспорте в PDF, HTML и PPT. При сохранении в PDF теперь можно выбрать метод сжатия иллюстраций, при сохранении в HTML и PPT – формат файлов с изображениями (JPEG или PNG). Настройки цветности и качества можно изменять как для отдельной картинки, так и для всех страниц пакета.
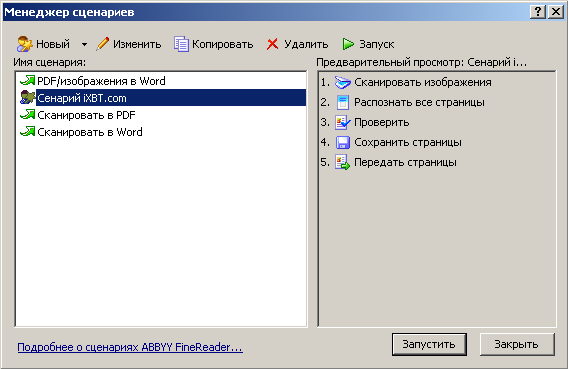
Автоматическая обработка документов - Процесс распознавания документов очень часто состоит из одного и того же набора операций. Например, сканирование, распознавание, сохранение распознанного текста в определённом формате. Для экономии времени пользователя в FineReader 8.0 предусмотрена возможность автоматизации однотипных действий. Для этого описано несколько наиболее распространённых сценариев обработки документов. Для запуска сценария достаточно просто нажать одну кнопку — вся остальная работа будет выполнена системой автоматически, в соответствии с настройками сценария.
Так, например, мы создали собственный сценарий, позволяющий сосканировать документ, распознать все страницы, проверить результат, сделать промежуточное сохранение в xls-файл и передать для работы в Microsoft Excel.
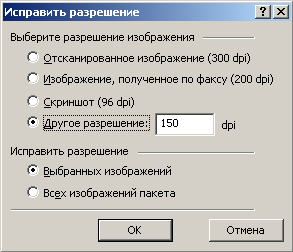
При предварительной обработке изображений появилась специальная опция исправления разрешения. Эта настройка увеличивает точность распознавания в тех случаях, когда изображение отсканировано с низким разрешением, получено с помощью цифровой камеры или представляет собой скриншот экрана. Если обрабатывать такие изображения без предварительной коррекции, качество окажется невысоким. Поэтому FineReader 8.0 при добавлении изображений в пакет проверяет каждое из них. В случаях, когда разрешение изображений оказывается неподходящим для системы оптического распознавания, автоматически производится его коррекция. При желании пользователь может устанавливать разрешение изображений вручную.
В ABBYY FineReader 8.0 появилась функция обрезания изображения; предусмотрены автоматический и ручной режимы. Функция предназначена для удаления чёрных полей (они иногда возникают при сканировании книг), для приведения страниц пакета к одинаковому размеру, для удаления с фотографий документов областей, не содержащих текста.
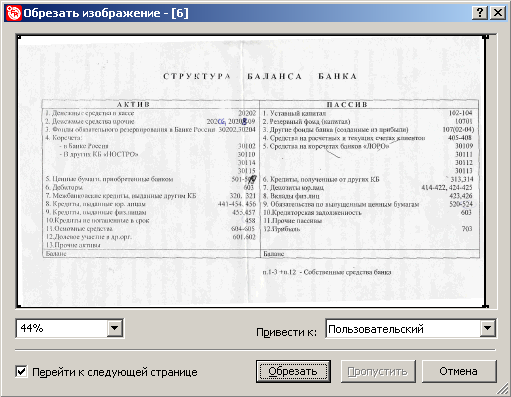
Одной из самых интересных новых функций, как мне кажется, стало «выпрямление» строк. Зачастую при сканировании толстых книг и журналов строки текста вблизи сгиба оказываются искривлены. Схожая проблема встречается при фотографировании: строки искривляются вблизи краёв документа. В восьмой версии FineReader появилась функция, позволяющая устранить подобные искажения и увеличить, таким образом, качество распознавания.
И, наверное, одно из наиболее весомых нововведений - поддержка технологий Intel Dual Core и Hyper-Threading, позволяющая повысить скорость распознавания в фоновом режиме при работе на современных процессорах Intel.
Для тех, кто ранее не работал с FineReader
Установка ABBYY FineReader проста и достаточно стандартна. Вставьте установочный диск в дисковод, программа установки должна запуститься автоматически.

Если пойти по пути выборочной установки, то новичка может поразить количество языков, доступных для распознавания. ABBYY FineReader 8.0 поддерживает 179 языков распознавания, включая 36 языков со словарной поддержкой. Пользователи, не нуждающиеся в распознавании, например, каталанского, эстонского или, скажем уйгурского языка, смело могут оставить лишь русский, английский, немецкий и французский языки. Кому-то, возможно, понадобится итальянский или испанский. Можно распознавать тексты, написанные на формальных языках, таких как языки программирования (Pascal, Basic, C/C++), можно работать с искусственными языками (эсперанто, идо, интерлингва). В общем - есть простор для выбора.
Процесс установки позволит вам выпить чашечку чая, даже если у вас мощный и быстрый компьютер. Сначала жесткий диск будет активно работать какое-то время, а потом уже пойдёт считывание данных с CD.
После установки, запустив программу, она попросит у вас осуществить активацию программы. Наиболее простой и оперативный способ - осуществить активацию через Интернет. В этом случае от вас не потребуется почти никаких действий и не составит никаких затруднений (разумеется, если программа приобретена легально).
После регистрации вас также попросят провести еще одну активацию, которая позволит работать с программой ABBYY Screenshot Reader, поставляющейся в составе FineReader 8.0. Об этой утилите мы расскажем немного позднее.
Для тех, кто не знаком с процессом сканирования и распознавания документов, наиболее оптимальным вариантом будет воспользоваться помощью «Мастера Scan&read», он пошагово проведёт через все этапы ввода и распознавания данных, в зависимости от исходного документа и требуемого результата.
Если вы случайно убрали «мастера», а как действовать дальше не представляете, то достаточно просто нажать на яркую кнопку «Scan&Read», либо на стрелочку правее от кнопки и выбрать нужное действие.
Если у вас нет желания вдаваться в подробности сканирования, то это всё, что вам нужно знать. Остальное FineReader сделает за вас всё сам. Программа, пожалуй, как никогда ранее дружественна неопытному пользователю, и даже при минимуме знаний о работе сканера и соответствующих приложений можно добиться нужных результатов.
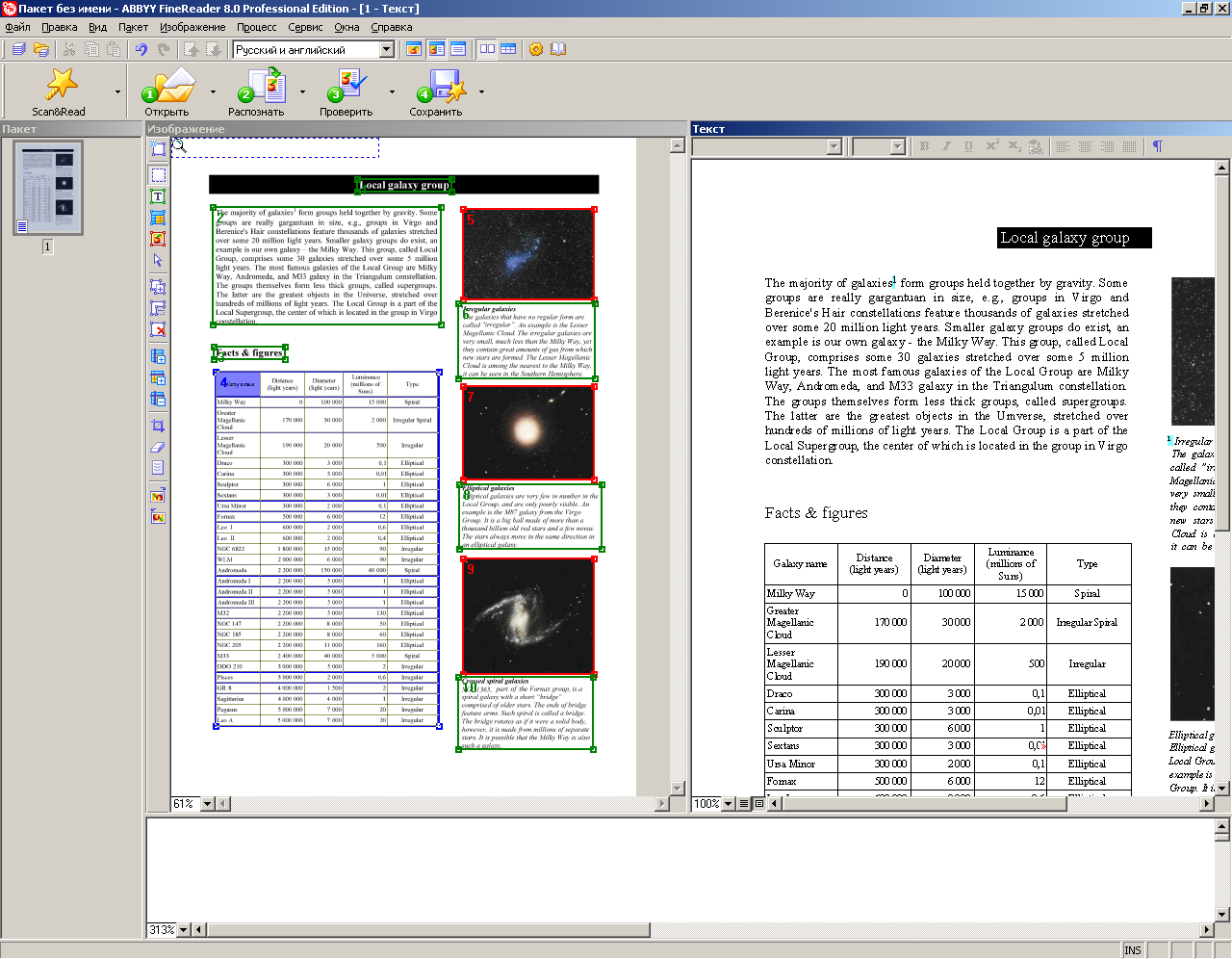
Интерфейс
Интерфейс программы почти не изменился со времён шестой версии, но это и понятно, функциональность и очевидность его достигла, пожалуй, своего оптимума еще в FineReader 6.0.
Распознавание: шаг за шагом
Более опытным пользователям, которые желают держать процесс распознавания под своим контролем, необходимо выполнить 4 шага.
Нажмите кнопку Сканировать (или Открыть, в зависимости от источника), чтобы начать сканирование. Откроется окно программы сканирования. В большинстве случаев оптимальным разрешением будет 300dpi, режим сканирования при этом лучше устанавливать, ориентируясь на то, какие элементы присутствуют в документе (только текст, текст с графиками или диаграммами, текст с иллюстрациями).
Для того, чтобы отсканировать несколько страниц подряд, нажмите на стрелку справа от кнопки Сканировать, выберите команду Опции... и в открывшемся диалоге Опции отметьте пункт Сканировать несколько страниц. В многостраничных PDF- и TIFF-файлах можно открыть не все страницы, а только те, что нужны вам. Для этого укажите номера (или диапазоны) страниц, разделяя их запятой, например: 1,2,8-12.
Далее, сосканированное изображение (или изображения) необходимо распознать. Распознать можно как текущее изображение, так и все изображения, введенные в рамках данной сессии в программу со сканера.
При этом помните, язык распознавания должен соответствовать языку, на котором написан документ. Для многоязычных документов можно указать несколько языков. Однако не рекомендуется выбирать более двух-трёх языков.
Пользователи, желающие распознавать и работать только с теми сегментами документа, которые нужны им, могут воспользоваться кнопкой «Анализ макета страницы». Наши читатели, которые давно работают с FineReader, эту кнопку знают больше как «Сегментирование».
Проверку можно осуществить вручную, пользуясь встроенным WYSIWYG-редактором, который обеспечивает максимально точное воспроизведение всех деталей оформления документа: колонки текста, таблицы и картинки отображаются в окне редактора точно так же, как они были расположены на исходном изображении. Это удобно: качество сохранения форматирования можно проверить сразу, не дожидаясь экспорта документа в Microsoft Word или веб-браузер.
Также можно воспользоваться диалогом Проверка, в котором показывается слово с ошибкой, его изображение на исходном документе и варианты замены. При этом следует учитывать, что подсвечиваются и отображаются в диалоге «Проверка» те слова, в которых есть неуверенно распознанные символы, то есть такие, для которых оценка уверенности самой лучшей гипотезы из всех, выдвинутых системой, меньше некоего заданного уровня. Вовсе не факт, что неуверенно распознанные символы - ошибочны.
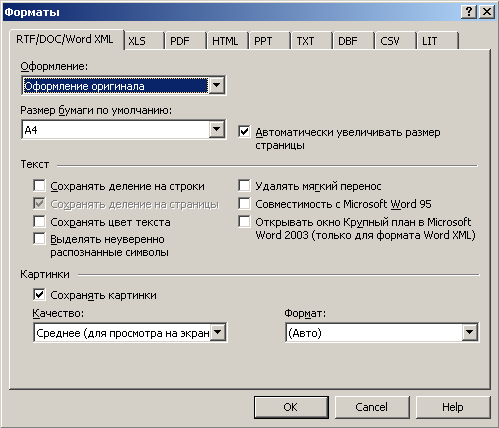
Для того, чтобы сохранить результаты распознавания в файл, нажмите на стрелку справа от кнопки Сохранить и выберите команду Сохранить страницы... Распознанный текст можно сохранить в следующих форматах: RTF, DOC, Word XML, XLS, PDF, HTML, PPT, TXT, DBF, CSV, LIT.
Разумеется, можно передать распознанный документ в соответствующее приложение, чтобы продолжить работу с ним с использованием привычных инструментов.
Для каждого формата можно выбрать настройки сохранения. Они находятся на соответствующей закладке диалога Форматы (настройки формата PDF находятся на закладке PDF и т.д.). Для того чтобы открыть диалог Форматы, нажмите на стрелку справа от кнопки Сохранить, выберите команду Опции... и в открывшемся диалоге нажмите кнопку Форматы...
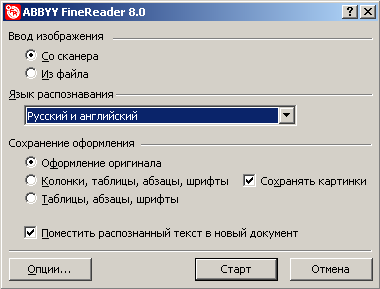
Интеграция FineReader в Microsoft Word
Интеграция FineReader в Microsoft Word позволяет обойтись без вызова «большого» FineReader, ограничившись лишь упрощённым интерфейсом. Это может быть достаточно удобно, когда вы точно знаете, что за документ вам нужно распознавать и дальнейшая обработка будет более рациональна в Word.
Вызов интерфейса осуществляется с помощью заметной красной кнопки, которая появляется на панели инструментов сразу после установки FineReader на компьютер.
К слову сказать, старый значок FineReader - некий техногенный глаз (знакомый многим пользователям еще по четвёртой версии FineReader) был куда более стильным, на мой взгляд, чем это «красное нечто», появившееся в FineReader 8.0.
Скорость распознавания
Читателей, ожидающих увидеть в данном разделе данные о возросшей в несколько раз скорости распознавания, мы вынуждены огорчить. Замеры, проведенные с секундомером на скорость распознавания идеального (с точки зрения программ распознавания) текста, напечатанного на листе А4 лазерным принтером 12-ым шрифтом, а также статьи, напечатанной в газете мелким шрифтом с истёртыми в некоторых местах строчками, показали, что на современном компьютере скорость распознавания в шестой и восьмой версиях почти одинакова. Выигрыш в скорости у FineReader 8.0 присутствует, но назвать его ошеломляющим нельзя. Экономия времени достигается в первую очередь за счёт более точного, а не более быстрого распознавания, а также при распознавании многолистовых документов. Тут FineReader 8.0 может помочь сэкономить полезные минуты, которые можно провести за другим занятием.
ABBYY Screenshot Reader
При помощи ABBYY Screenshot Reader вы можете создавать «снимки» экрана и распознавать находящиеся на «снимках» текст и таблицы. Результаты можно сохранять в файл, копировать в буфер обмена или экспортировать в Microsoft Word и Microsoft Excel.
Как мы уже говорили, для работы с данной утилитой необходимо пройти активацию. Сделано это, очевидно, в качестве одного из элементов средств защиты программы, но вот много ли потеряют люди, не воспользовавшиеся активацией в принципе, мы сейчас попробуем разобраться.
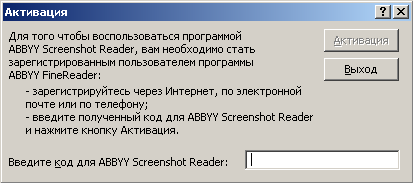
Говоря простым языком, ABBYY Screenshot Reader - приложение, которое позволяет распознавать текст с экрана компьютера. Для запуска ABBYY Screenshot Reader в меню Пуск выберите Программы -> ABBYY FineReader 8.0 -> ABBYY Screenshot Reader.
Внешний вид программы прост и незатейлив
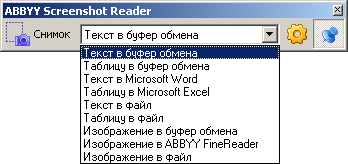
При нажатии на кнопку «Снимок» появляется сетка захвата, и если вы отметили некоторую область мышью, появится следующее окно:
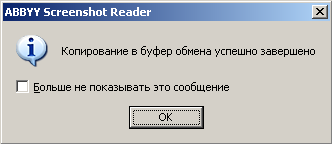
Далее появится окно, в котором необходимо указать язык распознавания скриншота и дополнительные настройки, в зависимости от наличия или отсутствия изображений в ранее выделенной области экрана.
Качество распознавания далеко от идеального, но приемлемо для быстрой и срочной обработки документа, который по каким-то причинам невозможно сохранить в одном из распространённых форматов.
В качестве примера мы «захватили» часть информации с html-странички, открытой в браузере...

... и перевели её в Word

как можно видеть, картинка, которая является также и ссылкой, распозналась некорректно.
При распознавании «захваченной» области текста с иллюстрациями также выявляются некоторые недочёты.

Так, если текст распознаётся корректно и правильно (даже если в слове допущена ошибка, как, например, со словом «тработает»), то иллюстрации передаются с искажениями.

«Захват» и распознавание таблиц также не лишён недостатков. Результат перевода таблицы, отображённый браузером в html (слева) можно посмотреть на правой иллюстрации.
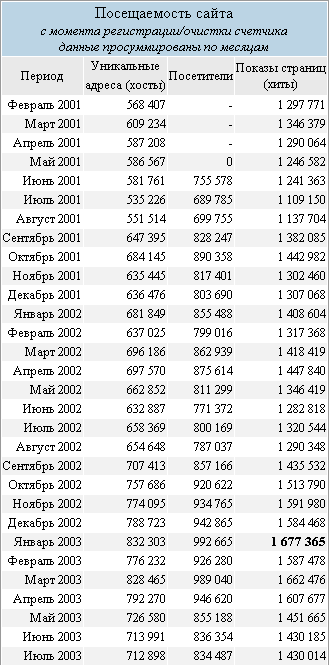 | 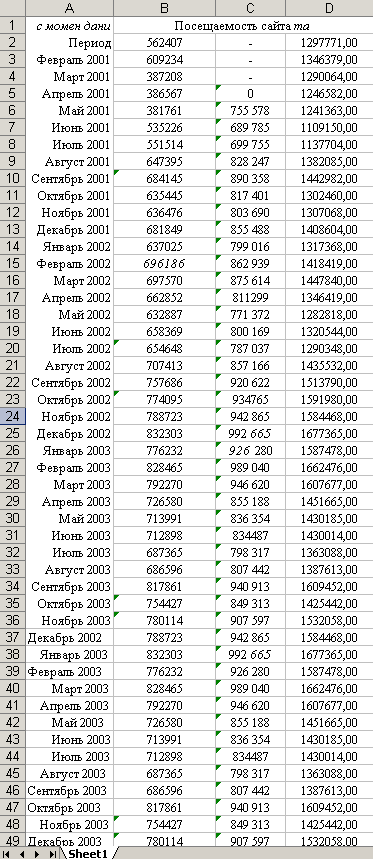 |
В общем и целом - всё неплохо и несколько упрощает задачу, если таблицу просто копировать через буфер и потом обрабатывать. Жаль, что некоторые досадные огрехи распознавания несколько портят общее впечатление. Так, первые 36 строк в первом столбце упорно преобразовывались в Excel как одна ячейка.
Утилита достаточно интересна просто, потому что реализует новые возможности. Реальное же её применение неочевидно. Редко когда требуется распознавать данные, уже представленные в цифровом виде.
Выводы
Новый продукт (а, точнее, обновлённый) ABBYY получился, как и ранее, - качественным и функциональным. Продуманный интерфейс, обилие настроек и возможностей, позволят пользователю эффективно экономить время, переводя в цифровой вид различные источники. Улучшенная работа с файлами формата PDF существенно расширяет функционал программы. Есть ли резон переходить на FineReader 8.0, с более ранних версий? Если ваша работа не ограничивается лишь сканированием пары страниц в месяц, а подразумевает интенсивную работу с документами, а также и с файлами в формате PDF, то резон есть, и он очевиден. Если для решения всех ваших задач вам хватает чётвёртой или пятой версии, то, как говорится, «лучшее - враг хорошего». Я свой выбор сделал, ABBYY FineReader 8.0 занял достойное место в списке программ, которые необходимо установить в первую очередь, после очередной переустановки Windows :-)
Комментарии