

Справочные материалы:
- Руководство покупателя игровой видеокарты
- Справочник по AMD Radeon HD 7xxx/Rx
- Справочник по Nvidia GeForce GTX 6xx/7xx/9xx/1xxx
- Возможности обработки видеопотоков Full HD
Теоретическая часть: особенности архитектуры
После довольно длительного застоя на рынке графических процессоров, связанного с несколькими факторами, наконец-то вышло новое поколение GPU компании Nvidia, да какое — с заявленным переворотом в 3D-графике реального времени! Действительно, аппаратно ускоренной трассировки лучей многие энтузиасты ждали уже давно, так как этот метод рендеринга олицетворяет физически корректный подход к делу, просчитывая путь лучей света, в отличие от растеризации с использованием буфера глубины, к которой мы привыкли за много лет и которая лишь имитирует поведение лучей света. Для того, чтобы не рассказывать об особенностях трассировки еще раз, мы предлагаем прочитать большую подробную статью о ней.
Хотя трассировка лучей обеспечивает более высокое качество картинки по сравнению с растеризацией, она весьма требовательна к ресурсам и ее применение ограничено возможностями аппаратного обеспечения. Анонс технологии Nvidia RTX и аппаратно поддерживающих ее GPU дал разработчикам возможность начать внедрение алгоритмов, использующих трассировку лучей, что является самым значительным изменением в графике реального времени за последние годы. Со временем она полностью изменит подход к рендерингу 3D-сцен, но это произойдет постепенно. Поначалу использование трассировки будет гибридным, при сочетании трассировки лучей и растеризации, но затем дело дойдет и до полной трассировки сцены, которая станет доступной через несколько лет.
Но что предлагает Nvidia прямо сейчас? Компания анонсировала свои игровые решения линейки GeForce RTX в августе, на игровой выставке Gamescom. GPU основаны на новой архитектуре Turing, представленной еще чуть ранее — на SIGGraph 2018, когда были рассказаны лишь некоторые подробности о новинках. Все недостающие детали мы и раскроем сегодня. В линейке GeForce RTX объявлено три модели: RTX 2070, RTX 2080 и RTX 2080 Ti, они основаны на трех графических процессорах: TU106, TU104 и TU102 соответственно. Сразу бросается в глаза, что с появлением аппаратной поддержки ускорения трассировки лучей Nvidia поменяла систему наименований и видеокарт (RTX — от ray tracing, т. е. трассировка лучей), и видеочипов (TU — Turing).

Почему Nvidia решила, что аппаратную трассировку необходимо представить именно сейчас? Ведь прорывов в технологии производства кремния нет, полноценное освоение нового техпроцесса 7 нм еще не закончено, особенно если говорить о массовом производстве таких больших и сложных GPU. И возможностей для заметного повышения количества транзисторов в чипе при сохранении приемлемой площади GPU практически нет. Выбранный для производства графических процессоров линейки GeForce RTX техпроцесс 12 нм FinFET хоть и лучше 16-нанометрового, известного нам по поколению Pascal, но эти техпроцессы весьма близки по своим основным характеристикам, 12-нанометровый использует схожие параметры, обеспечивая чуть большую плотность размещения транзисторов и сниженные утечки тока.
Но компания решила воспользоваться своим лидирующим положением на рынке высокопроизводительных графических процессоров, а также фактическим отсутствием конкуренции на данном этапе (лучшие из решений пока что единственного конкурента с трудом дотягивают до GeForce GTX 1080) и выпустить новинки с поддержкой аппаратной трассировки лучей именно в этом поколении — еще до возможности массового производства больших чипов по техпроцессу 7 нм. Видимо, чувствуют свою силу, иначе бы и не пробовали.
Кроме модулей трассировки лучей, в составе новых GPU есть и аппаратные блоки для ускорения задач глубокого обучения — тензорные ядра, которые достались Turing по наследству от Volta. И надо сказать, что Nvidia идет на приличный риск, выпуская игровые решения с поддержкой двух совершенно новых для пользовательского рынка типов специализированных вычислительных ядер. Главный вопрос заключается в том, смогут ли они получить достаточную поддержку от индустрии — с использованием новых возможностей и новых типов специализированных ядер. Для этого компании нужно убедить индустрию и продать критическую массу видеокарт GeForce RTX, чтобы разработчики увидели выгоду от внедрения новых фич. Ну а мы сегодня попробуем разобраться в том, насколько хороши улучшения в новой архитектуре и что может дать покупка старшей модели — GeForce RTX 2080 Ti.
Так как новая модель видеокарты компании Nvidia основана на графическом процессоре архитектуры Turing, имеющей много общего с предыдущими архитектурами Pascal и Volta, то перед прочтением данного материала мы советуем ознакомиться с нашими ранними статьями по теме:
- [14.09.18] Игровые видеокарты Nvidia GeForce RTX — первые мысли и впечатления
- [06.06.17] Nvidia Volta — новая вычислительная архитектура
- [09.03.17] GeForce GTX 1080 Ti — новый король игровой 3D-графики
- [17.05.16] GeForce GTX 1080 — новый лидер игровой 3D-графики на ПК
| Графический ускоритель GeForce RTX 2080 Ti | |
|---|---|
| Кодовое имя чипа | TU102 |
| Технология производства | 12 нм FinFET |
| Количество транзисторов | 18,6 млрд (у GP102 — 12 млрд) |
| Площадь ядра | 754 мм² (у GP102 — 471 мм²) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти | 352-битная: 11 (из 12 физически имеющихся в GPU) независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6 |
| Частота графического процессора | 1350 (1545/1635) МГц |
| Вычислительные блоки | 34 потоковых мультипроцессора, включающих 4352 CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32 |
| Тензорные блоки | 544 тензорных ядра для матричных вычислений INT4/INT8/FP16/FP32 |
| Блоки трассировки лучей | 68 RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 272 блока текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 11 (из 12 физически имеющихся в GPU) широких блоков ROP (88 пикселей) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка подключения по интерфейсам HDMI 2.0b и DisplayPort 1.4a |
| Спецификации референсной видеокарты GeForce RTX 2080 Ti | |
|---|---|
| Частота ядра | 1350 (1545/1635) МГц |
| Количество универсальных процессоров | 4352 |
| Количество текстурных блоков | 272 |
| Количество блоков блендинга | 88 |
| Эффективная частота памяти | 14 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 352-бит |
| Объем памяти | 11 ГБ |
| Пропускная способность памяти | 616 ГБ/с |
| Вычислительная производительность (FP16/FP32) | до 28,5/14,2 терафлопс |
| Производительность трассировки лучей | 10 гигалучей/с |
| Теоретическая максимальная скорость закраски | 136-144 гигапикселей/с |
| Теоретическая скорость выборки текстур | 420-445 гигатекселей/с |
| Шина | PCI Express 3.0 |
| Разъемы | один HDMI и три DisplayPort |
| Энергопотребление | до 250/260 Вт |
| Дополнительное питание | два 8-контактных разъема |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $999/$1199 или 95990 руб. (Founder’s Edition) |
Как это стало обычным делом уже для нескольких семейств видеокарт Nvidia, линейка GeForce RTX предлагает специальные модели самой компании — так называемые Founder’s Edition. В этот раз при более высокой стоимости они обладают и более привлекательными характеристиками. Так, фабричный разгон у таких видеокарт есть изначально, а кроме этого, GeForce RTX 2080 Ti Founder’s Edition выглядят весьма солидно благодаря удачному дизайну и отличным материалам. Каждая видеокарта протестирована на стабильную работу и обеспечивается трехлетней гарантией.

Видеокарты GeForce RTX Founder’s Edition имеют кулер с испарительной камерой на всю длину печатной платы и два вентилятора для более эффективного охлаждения. Длинная испарительная камера и большой двухслотовый алюминиевый радиатор обеспечивают большую площадь рассеивания тепла. Вентиляторы отводят горячий воздух в разные стороны, и при этом работают они довольно тихо.
Система питания в GeForce RTX 2080 Ti Founders Edition также серьезно усилена: применяется 13-фазная схема iMON DrMOS (в GTX 1080 Ti Founders Edition была 7-фазная dual-FET), поддерживающая новую динамическую систему управления питанием с более тонким контролем, улучшающая разгонные возможности видеокарты, о которых мы еще поговорим далее. Для питания скоростной GDDR6-памяти установлена отдельная трехфазная схема.
Архитектурные особенности
Сегодня мы рассматриваем старшую видеокарту GeForce RTX 2080 Ti, основанную на графическом процессоре TU102. Применяемая в этой модели модификация TU102 по количеству блоков ровно вдвое больше, чем TU106, который появится в виде модели GeForce RTX 2070 чуть позднее. TU102, применяемый в новинке, имеет площадь 754 мм² и 18,6 млрд транзисторов против 610 мм² и 15,3 млрд транзисторов у топового чипа семейства Pascal — GP100.
Примерно то же самое и с остальными новыми GPU, все они по сложности чипов как бы сдвинуты на шаг: TU102 соответствует TU100, TU104 по сложности похож на TU102, а TU106 — на TU104. Так как GPU усложнились, но техпроцессы применяются очень схожие, то и по площади новые чипы заметно увеличились. Посмотрим, за счет чего графические процессоры архитектуры Turing стали сложнее:
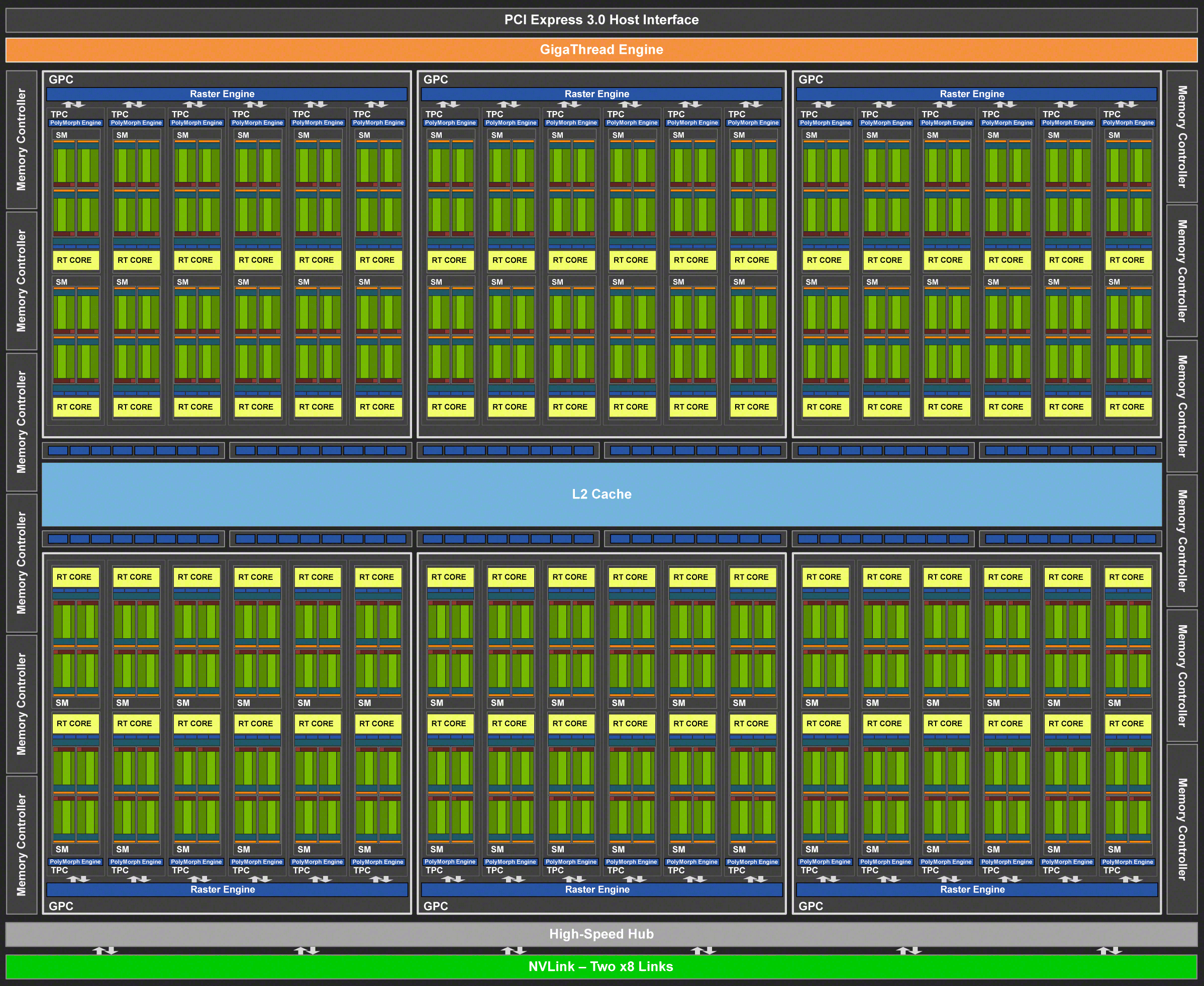
Полный чип TU102 включает шесть кластеров Graphics Processing Cluster (GPC), 36 кластеров Texture Processing Cluster (TPC) и 72 потоковых мультипроцессора Streaming Multiprocessor (SM). Каждый из кластеров GPC имеет собственный движок растеризации и шесть кластеров TPC, каждый из которых, в свою очередь, включает два мультипроцессора SM. Все SM содержат по 64 CUDA-ядра, по 8 тензорных ядер, по 4 текстурных блока, регистровый файл 256 КБ и 96 КБ конфигурируемого L1-кэша и разделяемой памяти. Для нужд аппаратной трассировки лучей каждый мультипроцессор SM имеет также и по одному RT-ядру.
Всего в полной версии TU102 получается 4608 CUDA-ядер, 72 RT-ядра, 576 тензорных ядер и 288 блоков TMU. Графический процессор общается с памятью при помощи 12 отдельных 32-битных контроллеров, что дает 384-битную шину в целом. К каждому контроллеру памяти привязаны по восемь блоков ROP и по 512 КБ кэш-памяти второго уровня. То есть всего в чипе 96 блоков ROP и 6 МБ L2-кэша.
По структуре мультипроцессоров SM новая архитектура Turing очень схожа с Volta, и количество ядер CUDA, блоков TMU и ROP по сравнению с Pascal выросло не слишком сильно — и это при таком усложнении и физическом увеличении чипа! Но это не удивительно, ведь основную сложность привнесли новые типы вычислительных блоков: тензорные ядра и ядра ускорения трассировки лучей.
Еще были усложнены сами CUDA-ядра, в которых появилась возможность одновременного исполнения целочисленных вычислений и операций с плавающей запятой, а также серьезно увеличен объем кэш-памяти. Об этих изменениях мы поговорим далее, а пока что отметим, что при проектировании семейства Turing разработчики намеренно перенесли фокус с производительности универсальных вычислительных блоков в пользу новых специализированных блоков.
Но не следует думать, что возможности CUDA-ядер остались неизменными, их тоже значительно улучшили. По сути, потоковый мультипроцессор Turing основан на варианте Volta, из которого исключена большая часть FP64-блоков (для операций с двойной точностью), но оставлена удвоенная производительность на такт для FP16-операций (также аналогично Volta). Блоков FP64 в TU102 оставлено 144 штуки (по два на SM), они нужны только для обеспечения совместимости. А вот вторая возможность позволит увеличить скорость и в приложениях, поддерживающих вычисления со сниженной точностью, вроде некоторых игр. Разработчики уверяют, что в значительной части игровых пиксельных шейдеров можно смело снизить точность с FP32 до FP16 при сохранении достаточного качества, что также принесет некоторый прирост производительности. Со всеми подробностями работы новых SM можно ознакомиться в обзоре архитектуры Volta.
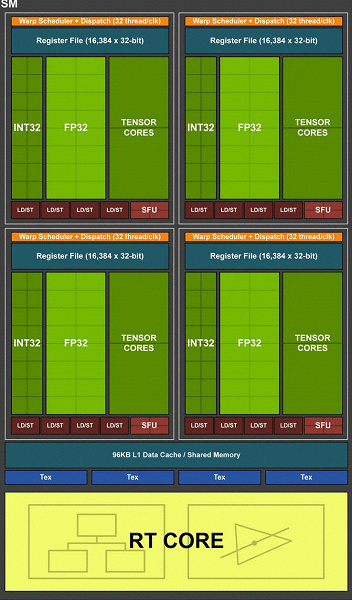
Одним из важнейших изменений потоковых мультипроцессоров является то, что в архитектуре Turing стало возможным одновременное выполнение целочисленных (INT32) команд вместе с операциями с плавающей запятой (FP32). Некоторые пишут, что в CUDA-ядрах «появились» блоки INT32, но это не совсем верно — они «появились» в составе ядер сразу, просто до архитектуры Volta одновременное исполнение целочисленных и FP-инструкций было невозможно, и эти операции запускались на выполнение по очереди. CUDA-ядра архитектуры Turing же схожи с ядрами Volta, которые позволяют исполнять INT32- и FP32-операции параллельно.
И так как игровые шейдеры, помимо операций с плавающей запятой, используют много дополнительных целочисленных операций (для адресации и выборки, специальных функций и т. п.), то это нововведение способно серьезно повысить производительность в играх. По оценкам компании Nvidia, в среднем на каждые 100 операций с плавающей запятой приходится около 36 целочисленных операций. Так что лишь это улучшение способно принести прирост скорости вычислений порядка 36%. Важно отметить, что это касается только эффективной производительности в типичных условиях, а на пиковых возможностях GPU не сказывается. То есть пусть теоретические цифры для Turing и не столь красивы, в реальности новые графические процессоры должны оказаться более эффективными.
Но почему, раз в среднем целочисленных операций лишь 36 на 100 FP-вычислений, количество блоков INT и FP одинаково? Скорее всего, это сделано для упрощения работы управляющей логики, а кроме этого, INT-блоки наверняка значительно проще FP, так что «лишнее» их количество вряд ли сильно повлияло на общую сложность GPU. Ну и задачи графических процессоров Nvidia давно не ограничиваются игровыми шейдерами, а в других применениях доля целочисленных операций вполне может быть и выше. Кстати, аналогично Volta повысился и темп выполнения инструкций для математических операций умножения-сложения с однократным округлением (fused multiply–add — FMA), требующих лишь четырех тактов по сравнению с шестью тактами на Pascal.
В новых мультипроцессорах SM была серьезно изменена и архитектура кэширования, для чего кэш первого уровня и разделяемая память были объединены (у Pascal они были раздельные). Shared-память ранее имела лучшие характеристики по пропускной способности и задержкам, а теперь пропускная способность L1-кэша выросла вдвое, снизились задержки доступа к нему вместе с одновременным увеличением емкости кэша. В новом GPU можно изменять соотношение объема L1-кэша и разделяемой памяти, выбирая из нескольких возможных конфигураций.
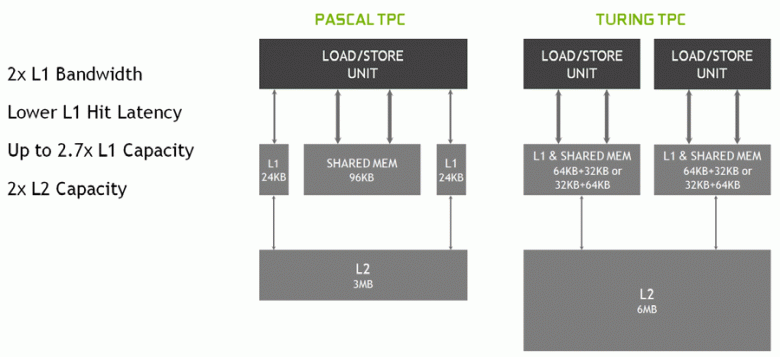
Кроме этого, в каждом разделе мультипроцессора SM появился L0-кэш для инструкций вместо общего буфера, а каждый кластер TPC в чипах архитектуры Turing теперь имеет вдвое больше кэш-памяти второго уровня. То есть общий объем L2-кэша вырос до 6 МБ для TU102 (у TU104 и TU106 его поменьше — 4 МБ).
Эти архитектурные изменения привели к 50%-ному улучшению производительности шейдерных процессоров при равной тактовой частоте в таких играх, как Sniper Elite 4, Deus Ex, Rise of the Tomb Raider и других. Но это не значит, что общий рост частоты кадров будет равен 50%, так как общая производительность рендеринга в играх далеко не всегда ограничена именно скоростью вычисления шейдеров.
Также были улучшены технологии сжатия информации без потерь, экономящие видеопамять и ее пропускную способность. Архитектура Turing поддерживает новые техники сжатия — по данным Nvidia, до 50% более эффективные по сравнению с алгоритмами в семействе чипов Pascal. Вместе с применением нового типа памяти GDDR6 это дает приличный прирост эффективной ПСП, так что новые решения не должны быть ограничены возможностями памяти. А при увеличении разрешения рендеринга и повышении сложности шейдеров ПСП играет важнейшую роль в обеспечении общей высокой производительности.
К слову, о памяти. Инженеры Nvidia работали совместно с производителями для обеспечения поддержки нового типа памяти — GDDR6, и все новое семейство GeForce RTX поддерживает микросхемы этого типа, имеющие пропускную способность в 14 Гбит/с и при этом на 20% более энергоэффективные по сравнению с применяемой в топовых Pascal GDDR5X-памятью. Топовый чип TU102 имеет 384-битную шину памяти (12 штук 32-битных контроллеров), но так как один из них отключен в GeForce RTX 2080 Ti, то шина памяти у него 352-битная, и на топовую карту семейства установлено 11, а не 12 ГБ.
Сама по себе GDDR6 хоть и является совершенно новым типом памяти, но слабо отличается от уже использовавшейся ранее GDDR5X. Основное ее отличие — в еще более высокой тактовой частоте при том же напряжении в 1,35 В. А от GDDR5 новый тип отличается тем, что имеет два независимых 16-битных канала с собственными шинами команд и данных — в отличие от единого 32-битного интерфейса GDDR5 и не полностью независимых каналов в GDDR5X. Это позволяет оптимизировать передачу данных, а более узкая 16-битная шина работает эффективнее.
Характеристики GDDR6 обеспечивают высокую пропускную способность памяти, которая стала значительно выше, чем была у предыдущего поколения GPU, поддерживающего типы памяти GDDR5 и GDDR5X. Рассматриваемая сегодня GeForce RTX 2080 Ti имеет ПСП на уровне 616 ГБ/с, что выше и чем у предшественников, и чем у конкурирующей видеокарты, использующей дорогую память стандарта HBM2. В будущем характеристики памяти GDDR6 будут улучшаться, сейчас ее выпускают компании Micron (скорость от 10 до 14 Гбит/с) и Samsung (14 и 16 Гбит/с).
Другие нововведения
Добавим немного информации о других нововведениях Turing, которые будут полезны и для старых, и для новых игр. К примеру, по некоторым фичам (feature level) из Direct3D 12 чипы Pascal отставали от решений AMD и даже Intel! В частности, это касается таких возможностей, как Constant Buffer Views, Unordered Access Views и Resource Heap (возможности, облегчающие работу программистов, упрощая доступ к различным ресурсам). Так вот, по этим возможностям Direct3D feature level новые GPU компании Nvidia теперь практически не отстают от конкурентов, поддерживая уровень Tier 3 для Constant Buffer Views и Unordered Access Views и Tier 2 для resource heap.
Единственная возможность D3D12, которая есть у конкурентов, но не поддерживается в Turing — PSSpecifiedStencilRefSupported: возможность вывести из пиксельного шейдера референсное значение стенсиля, иначе его можно установить только глобально для всего вызова функции отрисовки. В некоторых старых играх стенсиль использовался для отсечения источников освещения в различных регионах экрана, и эта возможность была полезна для занесения в стенсиль маски с несколькими разными значениями, чтобы каждому источнику света отрисовываться в своем проходе со стенсил-тестом. Без PSSpecifiedStencilRefSupported эту маску приходится рисовать в несколько проходов, а так можно сделать один, вычисляя значение стенсиля непосредственно в пиксельном шейдере. Вроде бы штука полезная, но в реальности не сильно важна — проходы эти несложные, и заполнение стенсиля в несколько проходов мало на что влияет при современных GPU.
Зато с остальным все в порядке. Появилась поддержка удвоенного темпа исполнения инструкций с плавающей запятой, и в том числе в Shader Model 6.2 — новой шейдерной модели DirectX 12, которая включает нативную поддержку FP16, когда вычисления производятся именно в 16-битной точности и драйвер не имеет права использовать FP32. Предыдущие GPU игнорировали установку min precision FP16, используя FP32, когда им вздумается, а в SM 6.2 шейдер может потребовать использование именно 16-битного формата.
Кроме этого, было серьезно улучшено еще одно больное место чипов Nvidia — асинхронное исполнение шейдеров, высокой эффективностью которого отличаются решения AMD. Async compute уже неплохо работал в последних чипах семейства Pascal, но в Turing эта возможность была еще улучшена. Асинхронные вычисления в новых GPU полностью переработаны, и на одном и том же шейдерном мультипроцессоре SM могут запускать и графические, и вычислительные шейдеры, как и чипы AMD.
Но и это еще не все, чем может похвастать Turing. Многие изменения в этой архитектуре нацелены на будущее. Так, Nvidia предлагает метод, позволяющий значительно снизить зависимость от мощности CPU и одновременно с этим во много раз увеличить количество объектов в сцене. Бич API/CPU overhead давно преследует ПК-игры, и хотя он частично решался в DirectX 11 (в меньшей степени) и DirectX 12 (в несколько большей, но все равно не полностью), радикально ничего не изменилось — каждый объект сцены требует нескольких вызовов функций отрисовки (draw calls), каждый из которых требует обработки на CPU, что не дает GPU показать все свои возможности.
Слишком многое сейчас зависит от производительности центрального процессора, и даже современные многопоточные модели не всегда справляются. Кроме этого, если минимизировать «вмешательство» CPU в процесс рендеринга, то можно открыть множество новых возможностей. Конкурент Nvidia при анонсе своего семейства Vega предложил возможное решение проблем — primivtive shaders, но дело не пошло дальше заявлений. Turing предлагает аналогичное решение под названием mesh shaders — это целая новая шейдерная модель, которая ответственна сразу за всю работу над геометрией, вершинами, тесселяцией и т. д.

Mesh shading заменяет вершинные и геометрические шейдеры и тесселяцию, а весь привычный вершинный конвейер заменяется аналогом вычислительных шейдеров для геометрии, которыми можно делать все, что нужно разработчику: трансформировать вершины, создавать их или убирать, используя вершинные буферы в своих целях как угодно, создавая геометрию прямо на GPU и отправляя ее на растеризацию. Естественно, такое решение может сильно снизить зависимость от мощности CPU при рендеринге сложных сцен и позволит создавать богатые виртуальные миры с огромным количеством уникальных объектов. Такой метод также позволит использовать более эффективное отбрасывание невидимой геометрии, продвинутые техники уровня детализации (LOD — level of detail) и даже процедурную генерацию геометрии.

Но столь радикальный подход требует поддержки от API — наверное, поэтому у конкурента дело дальше заявлений не пошло. Вероятно, в Microsoft работают над добавлением этой возможности, раз она востребована уже двумя основными производителями GPU, и в какой-то из будущих версий DirectX она появится. Ну а пока что ее можно использовать в OpenGL и Vulkan через расширения, а в DirectX 12 — при помощи специализированного NVAPI, который как раз и создан для внедрения возможностей новых GPU, еще не поддерживаемых в общепринятых API. Но так как это не универсальный для всех производителей GPU метод, то широкой поддержки mesh shaders в играх до обновления популярных графических API, скорее всего, не будет.
Еще одна интереснейшая возможность Turing называется Variable Rate Shading (VRS) — это шейдинг с переменным количеством сэмплов. Эта новая возможность дает разработчику контроль над тем, сколько выборок использовать в случае каждого из тайлов буфера размером 4×4 пикселя. То есть для каждого тайла изображения из 16 пикселей можно выбрать свое качество на этапе закраски пикселя — как меньшее, так и большее. Важно, что это не касается геометрии, так как буфер глубины и все остальное остается в полном разрешении.
Зачем это нужно? В кадре всегда есть участки, на которых легко можно понизить количество сэмплов закраски практически без потерь в качестве — к примеру, это части изображения, замыленные постэффектами типа Motion Blur или Depth of Field. А на каких-то участках можно, наоборот, увеличить качество закраски. И разработчик сможет задавать достаточное, по его мнению, качество шейдинга для разных участков кадра, что увеличит производительность и гибкость. Сейчас для подобных задач применяют так называемый checkerboard rendering, но он не универсален и ухудшает качество закраски для всего кадра, а с VRS можно делать это максимально тонко и точно.

Можно упрощать шейдинг тайлов в несколько раз, чуть ли не одну выборку для блока в 4×4 пикселя (такая возможность не показана на картинке, но она есть), а буфер глубины остается в полном разрешении, и даже при таком низком качестве шейдинга границы полигонов будут сохраняться в полном качестве, а не один на 16. К примеру, на картинке выше самые смазанные участки дороги рендерятся с экономией ресурсов вчетверо, остальные — вдвое, и лишь самые важные отрисовываются с максимальным качеством закраски. Так и в других случаях можно отрисовывать с меньшим качеством низкодетализированные поверхности и быстро движущиеся объекты, а в приложениях виртуальной реальности снижать качество закраски на периферии.
Кроме оптимизации производительности, эта технология дает и некоторые неочевидные сходу возможности, вроде почти бесплатного сглаживания геометрии. Для этого нужно отрисовывать кадр в вчетверо большем разрешении (как бы суперсэмплинг 2×2), но включить shading rate на 2×2 по всей сцене, что убирает стоимость вчетверо большей работы по закраске, но оставляет сглаживание геометрии в полном разрешении. Таким образом получается, что шейдеры исполняются лишь один раз на пиксель, но сглаживание получается как 4х MSAA практически бесплатно, поскольку основная работа GPU заключается именно в шейдинге. И это лишь один из вариантов использования VRS, наверняка программисты придумают и другие.
Нельзя не отметить и появление высокопроизводительного интерфейса NVLink второй версии, который уже используется в ускорителях высокопроизводительных вычислений Tesla. Топовый чип TU102 имеет два порта NVLink второго поколения, имеющие общую пропускную способность в 100 ГБ/с (к слову, в TU104 один такой порт, а TU106 лишен поддержки NVLink вовсе). Новый интерфейс заменяет разъемы SLI, а пропускной способности даже одного порта хватит для передачи кадрового буфера с разрешением 8К в режиме многочипового рендеринга AFR от одного GPU к другому, а передача буфера 4K-разрешения доступна на скоростях до 144 Гц. Два порта расширяют возможности SLI сразу до нескольких мониторов с разрешением 8K.
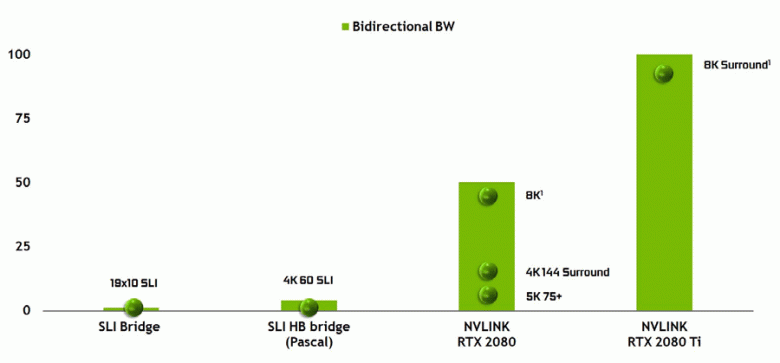
Такая высокая скорость передачи данных позволяет использовать локальную видеопамять соседнего GPU (присоединенного по NVLink, разумеется) практически как свою собственную, и это делается автоматически, без необходимости сложного программирования. Это будет весьма полезно в неграфических применениях и уже применяется в профессиональных приложениях с поддержкой аппаратной трассировки лучей (две видеокарты Quadro c 48 ГБ памяти каждая способны работать над сценой практически как единый GPU с 96 ГБ памяти, для чего ранее приходилось делать копии сцены в памяти обоих GPU), но в будущем это станет полезно и при более сложном взаимодействии многочиповых конфигураций в рамках возможностей DirectX 12. В отличие от SLI, быстрый обмен информацией по NVLink позволит организовать иные формы работы над кадром, чем AFR со всеми его недостатками.
Аппаратная поддержка трассировки лучей
Как стало известно из анонса архитектуры Turing и профессиональных решений линейки Quadro RTX на конференции SIGGraph, новые графические процессоры компании Nvidia, кроме ранее известных блоков, впервые включают также и специализированные RT-ядра, предназначенные для аппаратного ускорения трассировки лучей. Пожалуй, большая часть дополнительных транзисторов в новых GPU принадлежит именно к этим блокам аппаратной трассировки лучей, ведь количество традиционных исполнительных блоков выросло не слишком сильно, хотя и тензорные ядра немало повлияли на увеличение сложности GPU.
Nvidia сделала ставку на аппаратное ускорение трассировки при помощи специализированных блоков, и это большой шаг вперед для качественной графики в реальном времени. Мы уже публиковали большую подробную статью о трассировке лучей в реальном времени, гибридном подходе и его преимуществах, которые проявятся уже в ближайшее время. Настоятельно советуем ознакомиться, в этом материале мы расскажем о трассировке лучей лишь очень кратко.
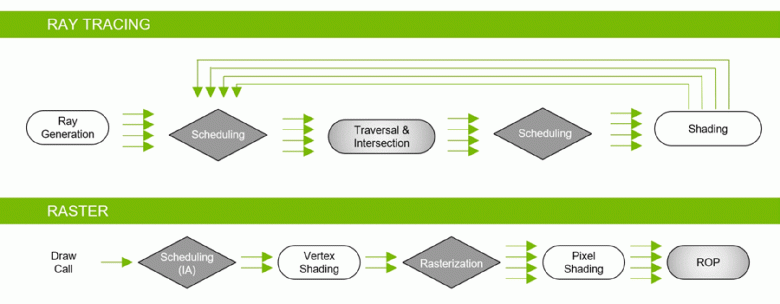
Благодаря семейству GeForce RTX уже сейчас можно использовать трассировку для некоторых эффектов: качественных мягких теней (реализовано в игре Shadow of the Tomb Raider), глобального освещения (ожидается в Metro Exodus и Enlisted), реалистичных отражений (будет в Battlefield V), а также сразу нескольких эффектов одновременно (показано на примерах Assetto Corsa Competizione, Atomic Heart и Control). При этом для GPU, не имеющих аппаратных RT-ядер в своем составе, можно использовать или привычные методы растеризации, или трассировку на вычислительных шейдерах, если это будет не слишком медленно. Вот так по-разному обрабатывают трассировку лучей архитектуры Pascal и Turing:
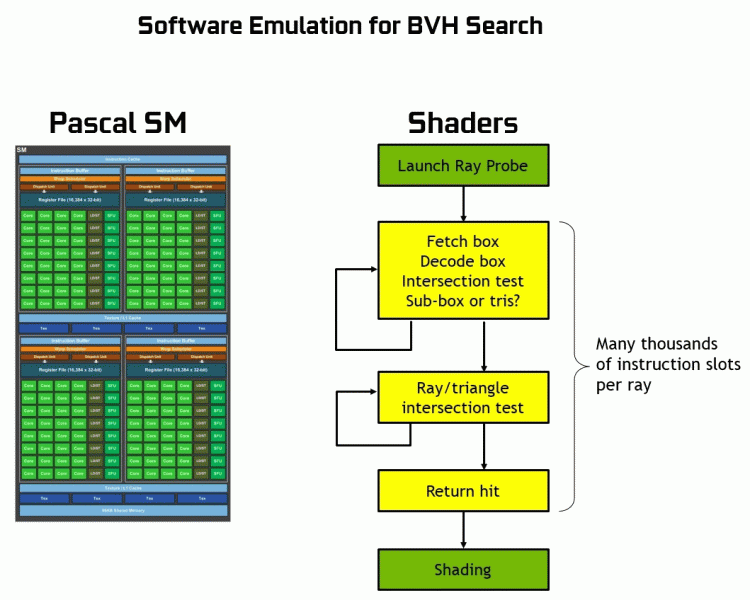
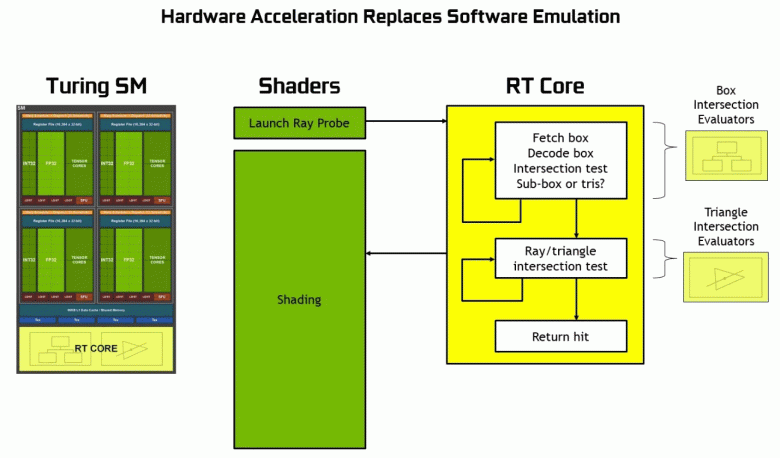
Как видите, RT-ядро полностью принимает на себя работу по определению пересечений лучей с треугольниками. Скорее всего, графические решения без RT-ядер в своем составе будут смотреться не слишком сильно в проектах с применением трассировки лучей, ведь эти ядра специализируются исключительно на расчетах пересечения луча с треугольниками и ограничивающими объемами (BVH), оптимизирующими процесс и важнейшими для ускорения процесса трассировки.
Каждый мультипроцессор в чипах Turing содержит RT-ядро, выполняющее поиск пересечений между лучами и полигонами, а чтобы не перебирать все геометрические примитивы, в Turing используется распространенный алгоритм оптимизации — иерархия ограничивающих объемов (Bounding Volume Hierarchy — BVH). Каждый полигон сцены принадлежит к одному из объемов (коробок), помогающих наиболее быстро определить точку пересечения луча с геометрическим примитивом. При работе BVH нужно рекурсивно обойти древовидную структуру таких объемов. Сложности могут возникнуть разве что для динамически изменяемой геометрии, когда придется менять и структуру BVH.
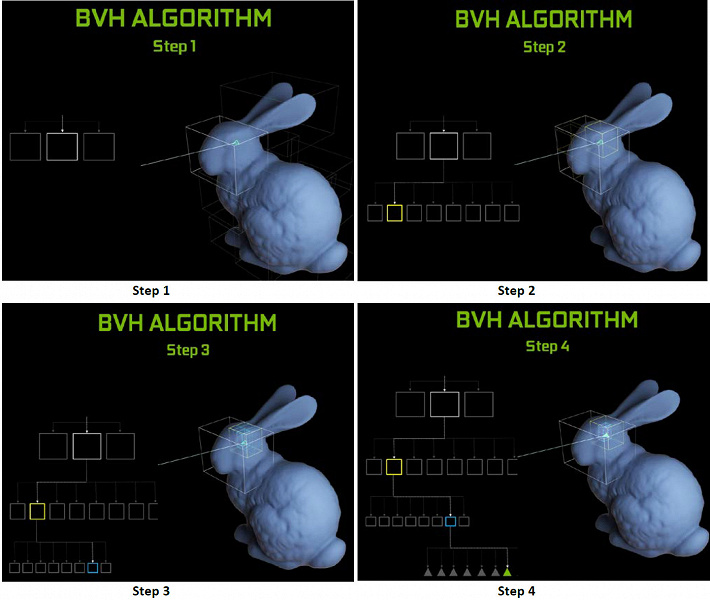
Что касается производительности новых GPU при трассировке лучей, то публике назвали цифру в 10 гигалучей в секунду для топового решения GeForce RTX 2080 Ti. Не очень понятно, много это или мало, да и оценивать производительность в количестве обсчитываемых лучей в секунду непросто, так как скорость трассировки очень сильно зависит от сложности сцены и когерентности лучей и может отличаться в десяток раз и более. В частности, слабо когерентные лучи при обсчете отражений и преломлений требуют большего времени для расчета по сравнению с когерентными основными лучами. Так что показатели эти чисто теоретические, а сравнивать разные решения нужно в реальных сценах при одинаковых условиях.
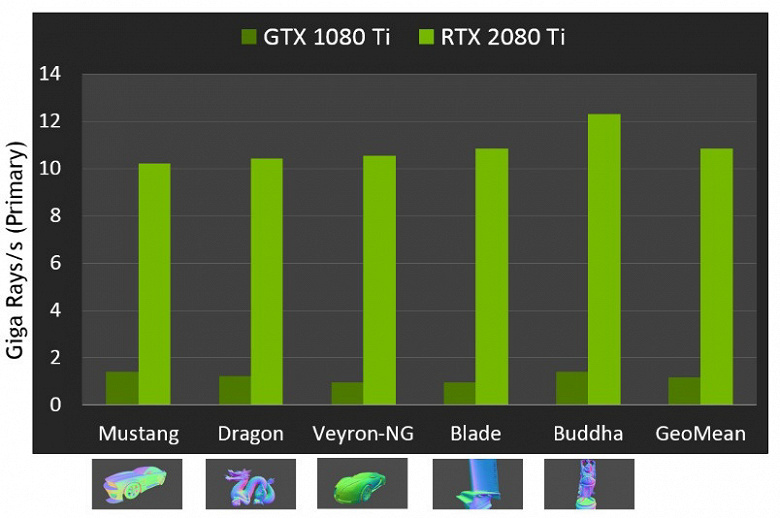
Но Nvidia сравнила новые GPU с предыдущим поколением, и в теории они оказались до 10 раз быстрее в задачах трассировки. В реальности же разница между RTX 2080 Ti и GTX 1080 Ti будет, скорее, ближе к 4-6-кратной. Но даже это — просто отличный результат, недостижимый без применения специализированных RT-ядер и ускоряющих структур типа BVH. Так как бо́льшая часть работы при трассировке выполняется на выделенных RT-ядрах, а не CUDA-ядрах, то снижение производительности при гибридном рендеринге будет заметно ниже, чем у Pascal.
Мы уже показывали вам первые демонстрационные программы с применением трассировки лучей. Некоторые из них были более зрелищными и качественными, другие впечатляли меньше. Но о потенциальных возможностях трассировки лучей не стоит судить по первым выпущенным демонстрациям, в которых намеренно выпячивают на первый план именно эти эффекты. Картинка с трассировкой лучей всегда реалистичнее в целом, но на данном этапе массы еще готовы мириться с артефактами при расчете отражений и глобального затенения в экранном пространстве, а также другими хаками растеризации.


Игровым разработчикам очень нравится трассировка, их аппетиты растут на глазах. Создатели игры Metro Exodus сначала планировали добавить в игру лишь расчет Ambient Occlusion, добавляющий теней в основном в углах между геометрией, но затем они решили внедрить уже полноценный расчет глобального освещения GI, который выглядит впечатляюще:
Кто-то скажет, что ровно так же можно предварительно рассчитать GI и/или тени и «запечь» информацию об освещении и тенях в специальные лайтмапы, но для больших локаций с динамическим изменением погодных условий и времени суток сделать это просто невозможно! Хотя растеризация при помощи многочисленных хитрых хаков и трюков действительно добилась отличных результатов, когда во многих случаях картинка выглядит достаточно реалистично для большинства людей, все же в некоторых случаях отрисовать корректные отражения и тени при растеризации невозможно физически.
Самый явный пример — отражения объектов, которые находятся вне сцены — типичными методами отрисовки отражений без трассировки лучей отрисовать их невозможно в принципе. Также не получится сделать реалистичные мягкие тени и корректно рассчитать освещение от больших по размеру источников света (площадные источники света — area lights). Для этого пользуются разными хитростями, вроде расставления вручную большого количества точечных источников света и фейкового размытия границ теней, но это не универсальный подход, он работает только в определенных условиях и требует дополнительной работы и внимания от разработчиков. Для качественного же скачка в возможностях и улучшении качества картинки переход к гибридному рендерингу и трассировке лучей просто необходим.
Трассировку лучей можно применять дозированно, для отрисовки определенных эффектов, которые сложно сделать растеризацией. Точно такой же путь в свое время проходила киноиндустрия, в которой в конце прошлого века применялся гибридный рендеринг с одновременной растеризацией и трассировкой. А еще через 10 лет все в кино постепенно перешли к полноценной трассировке лучей. То же самое будет и в играх, этот шаг с относительно медленной трассировкой и гибридным рендерингом невозможно пропустить, так как он дает возможность подготовиться к трассировке всего и вся.
Тем более, что во многих хаках растеризации уже и так используются схожие с трассировкой методы (к примеру, можно взять самые продвинутые методы имитации глобального затенения и освещения), поэтому более активное использование трассировки в играх — лишь дело времени. Заодно она позволяет упростить работу художников по подготовке контента, избавляя от необходимости расставлять фейковые источники света для имитации глобального освещения и от некорректных отражений, которые с трассировкой будут выглядеть естественно.
Переход к полной трассировке лучей (path tracing) в киноиндустрии привел к увеличению времени работы художников непосредственно над контентом (моделированием, текстурированием, анимацией), а не над тем, как сделать неидеальные методы растеризации реалистичными. К примеру, сейчас очень много времени уходит на расставление источников света, предварительный расчет освещения и «запекание» его в статические карты освещения. При полноценной трассировке это будет не нужно вовсе, и даже сейчас подготовка карт освещения на GPU вместо CPU даст ускорение этого процесса. То есть переход на трассировку обеспечит не только улучшение картинки, но и скачок в качестве самого контента.
В большинстве игр возможности GeForce RTX будут использоваться через DirectX Raytracing (DXR) — универсальный API Microsoft. Но для GPU без аппаратной/программной поддержки трассировки лучей также можно использовать D3D12 Raytracing Fallback Layer — библиотеку, которая эмулирует DXR при помощи вычислительных шейдеров. Эта библиотека имеет схожий, хоть и отличающийся интерфейс по сравнению с DXR, и это несколько разные вещи. DXR — это API, реализуемый непосредственно в драйвере GPU, он может быть реализован как аппаратно, так и полностью программно, на тех же вычислительных шейдерах. Но это будет разный код с разной производительностью. Вообще, изначально Nvidia не планировала поддерживать DXR на своих решениях до архитектуры Volta, но теперь и видеокарты семейства Pascal работают через DXR API, а не только через D3D12 Raytracing Fallback Layer.
Тензорные ядра для интеллекта
Потребности в производительности для работы нейросетей все большего размера и сложности постоянно растут, и в архитектуре Volta добавили новый тип специализированных вычислительных ядер — тензорные ядра. Они помогают получить многократный рост производительности по обучению и инференсу больших нейронных сетей, используемых в задачах искусственного интеллекта. Операции матричного перемножения лежат в основе обучения и инференса (выводы на основе уже обученной нейросети) нейронных сетей, они используются для умножения больших матриц входных данных и весов в связанных слоях сети.
Тензорные ядра специализируются на выполнении конкретно таких перемножений, они значительно проще универсальных ядер и способны серьезно увеличить производительность таких вычислений при сохранении сравнительно небольшой сложности в транзисторах и площади. Мы подробно писали обо всем этом в обзоре вычислительной архитектуры Volta. Кроме перемножения матриц FP16, тензорные ядра в Turing умеют оперировать и с целыми числами в форматах INT8 и INT4 — с еще большей производительностью. Такая точность подходит для применения в некоторых нейросетях, не требующих высокой точности представления данных, зато скорость расчетов возрастает еще вдвое и вчетверо. Пока что экспериментов с использованием пониженной точности не очень много, но потенциал ускорения в 2-4 раза может открыть новые возможности.
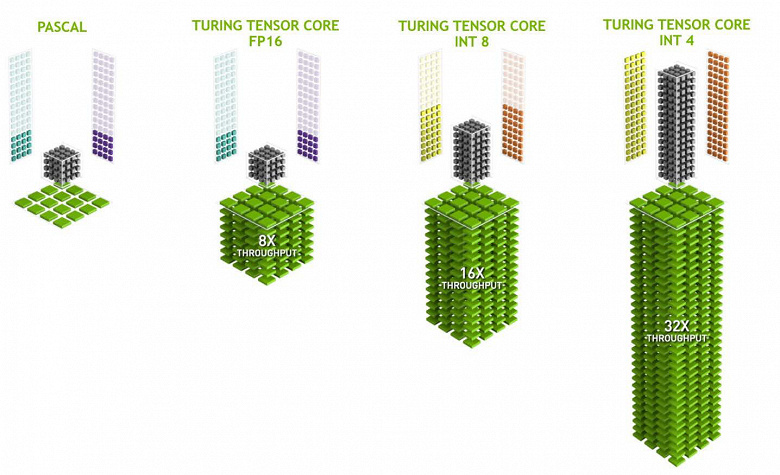
Важно, что эти операции можно выполнять параллельно с CUDA-ядрами, только FP16-операции в последних использует то же самое «железо», что и тензорные ядра, поэтому FP16 нельзя исполнять параллельно на CUDA-ядрах и на тензорных. Тензорные ядра могут исполнять или тензорные инструкции, или FP16-инструкции, и в этом случае их возможности используются не полностью. Скажем, сниженная точность FP16 дает прирост в темпе вдвое по сравнению с FP32, а использование тензорной математики — в 8 раз. Но тензорные ядра — специализированные, они не очень хорошо подходят для произвольных вычислений: умеют выполнять только матричное перемножение в фиксированной форме, которое используется в нейронных сетях, но не в обычных графических применениях. Впрочем, вполне возможно, что игровые разработчики придумают и другие применения тензорам, не связанные с нейросетями.
Но и задачи с применением искусственного интеллекта (глубокое обучение) уже сейчас применяют широко, в том числе они появятся и в играх. Главное, для чего потенциально нужны тензорные ядра в GeForce RTX — для помощи все той же трассировке лучей. На начальной стадии применения аппаратной трассировки производительности хватает только для сравнительно малого количества рассчитываемых лучей на каждый пиксель, а малое количество рассчитываемых сэмплов дает весьма «шумную» картинку, которую приходится обрабатывать дополнительно (подробности читайте в нашей статье о трассировке).
В первых игровых проектах обычно применяется расчет от 1 до 3-4 лучей на пиксель, в зависимости от задачи и алгоритма. К примеру, в ожидаемой в следующем году игре Metro Exodus для расчета глобального освещения с применением трассировки используется по три луча на пиксель с расчетом одного отражения, и без дополнительной фильтрации и шумопонижения результат к применению не слишком пригоден.

Для решения этой проблемы можно использовать различные фильтры шумопонижения, улучшающие результат без необходимости увеличения количества выборок (лучей). Шумодавы очень эффективно устраняют неидеальность результата трассировки со сравнительно малым количеством выборок, и результат их работы зачастую почти не отличить от изображения, полученного с помощью в разы большего количества выборок. На данный момент в Nvidia используют различные шумодавы, в том числе основанные на работе нейросетей, которые как раз и могут быть ускорены на тензорных ядрах.
В будущем такие методы с применением ИИ будут улучшаться, они способны полностью заменить все остальные. Главное, что нужно понять: на текущем этапе применениям трассировки лучей без фильтров шумоподавления не обойтись, именно поэтому тензорные ядра обязательно нужны в помощь RT-ядрам. В играх нынешние реализации пока что не используют тензорные ядра, у Nvidia хоть и есть реализация шумоподавления при трассировке, которая использует тензорные ядра — в OptiX, но из-за скорости работы алгоритма его пока что не получается применить в играх. Но его наверняка можно упростить, чтобы использовать в том числе и в игровых проектах.
Однако использовать искусственный интеллект (ИИ) и тензорные ядра можно не только для этой задачи. Nvidia уже показывала новый метод полноэкранного сглаживания — DLSS (Deep Learning Super Sampling). Его правильнее назвать улучшителем качества картинки, потому что это не привычное сглаживание, а технология, использующая искусственный интеллект для улучшения качества отрисовки аналогично сглаживанию. Для работы DLSS нейросеть сначала «тренируют» в офлайне на тысячах изображений, полученных с применением суперсэмплинга с количеством выборок 64 штуки, а затем уже в реальном времени на тензорных ядрах исполняются вычисления (инференс), которые «дорисовывают» изображение.

То есть нейросеть на примере тысяч хорошо сглаженных изображений из конкретной игры учат «додумывать» пиксели, делая из грубой картинки сглаженную, и она затем успешно делает это уже для любого изображения из той же игры. Такой метод работает значительно быстрее любого традиционного, да еще и с лучшим качеством — в частности, вдвое быстрее, чем GPU предыдущего поколения с использованием традиционных методов сглаживания типа TAA. У DLSS пока что есть два режима: обычный DLSS и DLSS 2x. Во втором случае рендеринг осуществляется в полном разрешении, а в упрощенном DLSS используется сниженное разрешение рендеринга, но обученная нейросеть дорисовывает кадр до полного разрешения экрана. В обоих случаях DLSS дает более высокое качество и стабильность по сравнению с TAA.
К сожалению, у DLSS есть один немаловажный недостаток: для внедрения этой технологии нужна поддержка со стороны разработчиков, так как для работы метода требуются данные из буфера с векторами движения. Но таких проектов уже довольно много, на сегодняшний день есть 25 поддерживающих эту технологию игр, включая такие известные, как Final Fantasy XV, Hitman 2, PlayerUnknown’s Battlegrounds, Shadow of the Tomb Raider, Hellblade: Senua’s Sacrifice и другие.

Но и DLSS — это еще не все, для чего можно применять нейросети. Все зависит от разработчика, он может использовать мощь тензорных ядер для более «умного» игрового ИИ, улучшенной анимации (такие методы уже есть), да много чего еще можно придумать. Главное, что возможности применения нейросетей фактически безграничны, мы просто еще даже не догадываемся о том, что́ можно сделать с их помощью. Раньше производительности было слишком мало для того, чтобы применять нейросети массово и активно, а теперь, с появлением тензорных ядер в простых игровых видеокартах (пусть пока только дорогих) и возможностью их использования при помощи специального API и фреймворка Nvidia NGX (Neural Graphics Framework), это становится всего лишь делом времени.
Автоматизация разгона
Видеокарты Nvidia давно используют динамическое повышение тактовой частоты в зависимости от загрузки GPU, питания и температуры. Этот динамический разгон контролируется алгоритмом GPU Boost, постоянно отслеживающим данные от встроенных сенсоров и меняющим характеристики GPU по частоте и напряжению питания в попытках выжать максимум возможной производительности из каждого приложения. Четвертое поколение GPU Boost добавляет возможность ручного управления алгоритмом работы разгона GPU Boost.
Алгоритм работы в GPU Boost 3.0 был полностью зашит в драйвере, и пользователь никак не мог повлиять на него. А в GPU Boost 4.0 ввели возможность ручного изменения кривых для увеличения производительности. К линии температур можно добавить несколько точек, и вместо прямой теперь используется ступенчатая линия, а частота не сбрасывается до базовой сразу же, обеспечивая бо́льшую производительность при определенных температурах. Пользователь может изменить кривую самостоятельно для достижения более высокой производительности.
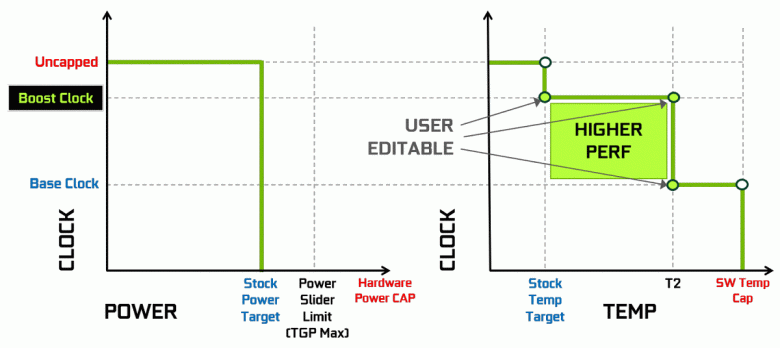
Кроме этого, впервые появилась такая новая возможность, как автоматизированный разгон. Это энтузиасты умеют разгонять видеокарты, но к ним относятся далеко не все пользователи, и не все могут или хотят заниматься ручным подбором характеристик GPU для повышения производительности. В Nvidia решили облегчить задачу для обычных пользователей, позволив каждому разогнать свои GPU буквально нажатием одной кнопки — при помощи Nvidia Scanner.
Nvidia Scanner запускает отдельный поток для тестирования возможностей GPU, который использует математический алгоритм, автоматически определяющий ошибки в расчетах и стабильность работы видеочипа на разных частотах. То есть то, что обычно делается энтузиастом на протяжении нескольких часов, с зависаниями, перезагрузками и прочими фокусами, теперь может сделать автоматизированный алгоритм, требующий на перебор всех возможностей не более 20 минут. Для прогрева и тестирования GPU при этом используются встроенные в чип специальные тесты. Технология закрытая, поддерживается пока только семейством GeForce RTX, и на Pascal она вряд ли заработает.

Эта возможность уже внедрена в такой известный инструмент как MSI AfterBurner. Пользователю этой утилиты доступно два основных режима: «Тест», в котором проверяется стабильность разгона GPU, и «Сканирование», когда алгоритмы Nvidia подбирают максимальные настройки разгона автоматически.
В режиме тестирования выдается результат стабильности работы в процентах (100% — полностью стабильно), а в режиме сканирования результат выводится в виде уровня разгона ядра в МГц, а также в виде измененной кривой частот/напряжения. Тестирование в MSI AfterBurner занимает около 5 минут, сканирование — 15-20 минут. В окне редактора кривой частот/напряжений можно увидеть текущие частоту и напряжение GPU, контролируя разгон. В режиме сканирования тестируется не вся кривая, а лишь несколько точек в выбранном диапазоне напряжений, в которых работает чип. Затем алгоритм находит максимально стабильный разгон для каждой из точек, повышая частоту при фиксированном напряжении. По завершении процесса OC Scanner пересылает в MSI Afterburner модифицированную кривую частот/напряжений.
Конечно, это далеко не панацея, и опытный любитель разгона выжмет из GPU еще больше. Да и автоматические средства разгона нельзя назвать абсолютно новыми, они существовали и раньше, хотя и показывали недостаточно стабильные и высокие результаты — разгон вручную практически всегда давал лучший результат. Однако, как отмечает Алексей Николайчук, автор MSI AfterBurner, технология Nvidia Scanner явно превосходит все предыдущие аналогичные средства. За время его испытаний этот инструмент ни разу не привел к краху ОС и всегда показывал стабильные (и достаточно высокие — порядка +10%-12%) частоты в результате. Да, GPU может зависать в процессе сканирования, но Nvidia Scanner всегда сам восстанавливает работоспособность и снижает частоты. Так что алгоритм реально неплохо работает и на практике.
Декодирование видеоданных и видеовыходы
Требования пользователей к поддержке устройств вывода постоянно растут — им хочется все бо́льших разрешений и максимального количества одновременно поддерживаемых мониторов. Самые продвинутые устройства имеют разрешение 8K (7680×4320 пикселей), требующее вчетверо большей пропускной способности по сравнению с 4K-разрешением (3820×2160), а энтузиасты компьютерных игр хотят максимально высокой частоты обновления информации на дисплеях — до 144 Гц и даже более.
Графические процессоры семейства Turing содержат новый блок вывода информации, поддерживающий новые дисплеи с высоким разрешением, HDR и высокую частоту обновления. В частности, видеокарты линейки GeForce RTX имеют порты DisplayPort 1.4a, позволяющие вывести информацию на 8K-монитор с частотой обновления 60 Гц с поддержкой технологии VESA Display Stream Compression (DSC) 1.2, обеспечивающей высокую степень сжатия.

Платы Founder’s Edition содержат три выхода DisplayPort 1.4a, один разъем HDMI 2.0b (с поддержкой HDCP 2.2) и один VirtualLink (USB Type-C), предназначенный для будущих шлемов виртуальной реальности. Это новый стандарт подключения VR-шлемов, обеспечивающий передачу питания и высокую пропускную способность по USB-C. Такой подход значительно облегчает подключение шлемов. VirtualLink поддерживает четыре линии High BitRate 3 (HBR3) DisplayPort и линк SuperSpeed USB 3 для отслеживания движения шлема. Естественно, что использование разъема VirtualLink/USB Type-C требует дополнительного питания — до 35 Вт в плюс к объявленным 260 Вт типичного энергопотребления у GeForce RTX 2080 Ti.
Все решения семейства Turing поддерживают два 8K-дисплея при 60 Гц (требуется по одному кабелю на каждый), такое же разрешение также можно получить при подключении через установленный USB-C. Кроме этого, все Turing поддерживают полноценный HDR в конвейере вывода информации, включая tone mapping для различных мониторов — со стандартным динамическим диапазоном и широким.
Также новые GPU имеют улучшенный кодировщик видеоданных NVENC, добавляющий поддержку компрессии данных в формате H.265 (HEVC) при разрешении 8K и 30 FPS. Новый блок NVENC снижает требования к полосе пропускания до 25% при формате HEVC и до 15% при формате H.264. Также был обновлен и декодер видеоданных NVDEC, получивший поддержку декодирования данных в формате HEVC YUV444 10-бит/12-бит HDR при 30 FPS, в формате H.264 при 8K-разрешении и в формате VP9 с 10-бит/12-бит данными.
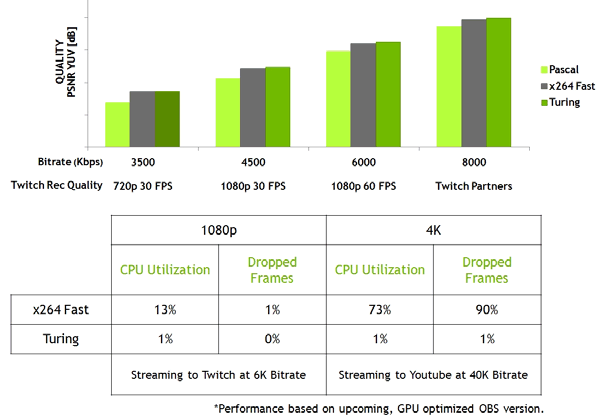
Семейство Turing еще и улучшает качество кодирования по сравнению с предыдущим поколением Pascal и даже по сравнению с программными кодировщиками. Кодировщик в новых GPU превосходит по качеству программный кодировщик x264, использующий быстрые (fast) настройки при значительно меньшем использовании ресурсов процессора. К примеру, стриминг видео в 4K-разрешении слишком тяжел для программных методов, а аппаратное кодирование видео на Turing способно исправить положение.
Выводы по теоретической части
Возможности Turing и GeForce RTX выглядят впечатляюще, в новых GPU были улучшены уже известные нам по предыдущим архитектурам блоки, а также появились совершенно новые, с новыми возможностями. CUDA-ядра новой архитектуры получили важные улучшения, которые обещают прирост в эффективности (производительности в реальных приложениях) даже при не слишком большом увеличении количества вычислительных блоков. А поддержка нового типа памяти GDDR6 и улучшенная подсистема кэширования должны позволить вытянуть из новых GPU весь их потенциал.
Появление абсолютно новых специализированных блоков аппаратного ускорения и глубокого обучения обеспечивает совершенно новые возможности, которые только начинают раскрываться. Да, пока что мощностей даже аппаратно ускоренной трассировки лучей на GeForce RTX не хватит для полной трассировки (path tracing), но это сейчас и не нужно — для заметного улучшения качества достаточно применения гибридного рендеринга и трассировки лучей только в тех задачах, где это полезнее всего — для отрисовки реалистичных отражений и преломлений, мягких теней и настоящего GI. И вот для этого новая линейка GeForce RTX вполне подходит, становясь первенцем перехода на полную трассировку лучей когда-нибудь в будущем.
Не бывает так, чтобы сразу же стало возможным кардинальное улучшение качества рендеринга, все произойдет постепенно, но для этого на данном этапе нужно аппаратное ускорение трассировки лучей. Да, Nvidia сейчас сделала шаг в сторону от всеобщей универсализации GPU, к которой все вроде бы все шло. Трассировка лучей и глубокое обучение — новые технологии и сферы применения графических процессоров, и видения «универсальной» поддержки для них еще пока нет. Зато можно получить серьезный прирост производительности при помощи специализированных блоков (RT-ядра и тензорные), которые помогут найти правильный путь для универсализации в будущем.
Ровно так же до внедрения пиксельных и вершинных шейдеров в графике долгое время использовался фиксированный, не универсальный подход. Но со временем индустрия поняла, каким должен быть полностью программируемый GPU для растеризации, и на это ушли годы работы над специализированными блоками. Вероятно, это же самое ожидает и трассировку лучей и глубокое обучение. Но этап аппаратной поддержки в специализированных блоках позволяет ускорить процесс, раскрыть многие возможности раньше.
Спорные моменты в связи с выходом семейства GeForce RTX тоже есть. Во-первых, новинки могут не обеспечить ускорения в некоторых из существующих игр и приложений. Дело в том, что не все они смогут получить преимущество за счет улучшенных блоков CUDA, а количество этих блоков выросло не сильно. То же самое касается и текстурных блоков и блоков ROP. Не говоря уже о том, что даже нынешние GeForce GTX 1080 Ti часто упираются в CPU в разрешениях 1920×1080 и 2560×1440. Есть немалая вероятность того, что в текущих приложениях прирост производительности не оправдает ожиданий многих пользователей. Тем более, что цена новинки... не просто высока, а очень высока!
И в этом — главный спорный момент. Очень многих потенциальных покупателей смущают объявленные цены на новые решения Nvidia, и цены действительно высоки, особенно в условиях нашей страны. Конечно, всему есть объяснения: и отсутствие конкуренции со стороны AMD, и высокая себестоимость проектирования и производства новых GPU, и особенности национального ценообразования... Но кто может себе позволить отдать под 100 тысяч рублей за топовую GeForce RTX 2080 Ti или даже 64 и 48 тысяч за менее мощные варианты? Конечно, такие энтузиасты есть, и первые партии новых видеокарт уже раскуплены любителями всего лучшего и самого нового. Но так случается всегда, а вот что будет, когда первые партии закончатся, как и небедные энтузиасты?
Конечно, в Nvidia имеют право назначать любые цены, но только время покажет, были они правы с установкой таких цен или нет. В конечном итоге все решит спрос, ведь покупать новые видеокарты или нет — дело покупателей. Если те посчитают, что цена на продукт завышена, то спрос будет низкий, доход и прибыль компании Nvidia упадет и им придется снижать цены, чтобы был больший оборот при меньшей прибыли с каждой видеокарты. Но для этого нужно время, а пока что серьезного снижения цен ждать не приходится. Тем более, что решения семейства RTX 2000 действительно инновационные и обеспечивают лучшую производительность в широком круге задач плюс очень интересные новые возможности.
Особенности видеокарты
Объект исследования: ускоритель трехмерной графики (видеокарта) Nvidia GeForce RTX 2080 Ti 11 ГБ 352-битной GDDR6


Сведения о производителе: Компания Nvidia Corporation (торговая марка Nvidia) основана в 1993 году в США.Штаб-квартира в Санта-Кларе (Калифорния). Разрабатывает графические процессоры, технологии. До 1999 года основной маркой была Riva (Riva 128/TNT/TNT2), с 1999 года и по настоящее время — GeForce. В 2000 году были приобретены активы 3dfx Interactive, после чего торговые марки 3dfx/Voodoo перешли к Nvidia. Своего производства нет. Общая численность сотрудников (включая региональные офисы) — около 5000 человек.
Характеристики референс-карты
| Nvidia GeForce RTX 2080 Ti 11 ГБ 352-битной GDDR6 | ||
|---|---|---|
| Параметр | Номинальное значение (референс) | |
| GPU | GeForce RTX 2080 Ti (TU102) | |
| Интерфейс | PCI Express x16 | |
| Частота работы GPU (ROPs), МГц | 1650—1950 | |
| Частота работы памяти (физическая (эффективная)), МГц | 3500 (14000) | |
| Ширина шины обмена с памятью, бит | 352 | |
| Число вычислительных блоков в GPU | 68 | |
| Число операций (ALU) в блоке | 64 | |
| Суммарное количество блоков ALU | 4352 | |
| Число блоков текстурирования (BLF/TLF/ANIS) | 272 | |
| Число блоков растеризации (ROP) | 88 | |
| Размеры, мм | 270×100×36 | |
| Количество слотов в системном блоке, занимаемые видеокартой | 2 | |
| Цвет текстолита | черный | |
| Энергопотребление пиковое в 3D, Вт | 264 | |
| Энергопотребление в режиме 2D, Вт | 30 | |
| Энергопотребление в режиме «сна», Вт | 11 | |
| Уровень шума в 3D (максимальная нагрузка), дБА | 39,0 | |
| Уровень шума в 2D (просмотр видео), дБА | 26,1 | |
| Уровень шума в 2D (в простое), дБА | 26,1 | |
| Видеовыходы | 1×HDMI 2.0b, 3×DisplayPort 1.4, 1×USB-C (VirtualLink) | |
| Поддержка многопроцессорной работы | SLI | |
| Максимальное количество приемников/мониторов для одновременного вывода изображения | 4 | |
| Питание: 8-контактные разъемы | 2 | |
| Питание: 6-контактные разъемы | 0 | |
| Максимальное разрешение/частота, Display Port | 3840×2160@160 Гц (7680×4320@30 Гц) | |
| Максимальное разрешение/частота, HDMI | 3840×2160@60 Гц | |
| Максимальное разрешение/частота, Dual-Link DVI | 2560×1600@60 Гц (1920×1200@120 Гц) | |
| Максимальное разрешение/частота, Single-Link DVI | 1920×1200@60 Гц (1280×1024@85 Гц) | |
Память

Карта имеет 11 ГБ памяти GDDR6 SDRAM, размещенной в 11 микросхемах по 8 Гбит на лицевой стороне PCB. Микросхемы памяти Micron (GDDR6) рассчитаны на номинальную частоту работы в 3500 (14000) МГц.
Особенности карты и сравнение с предыдущим поколением
| Nvidia GeForce RTX 2080 Ti (11 ГБ) | Nvidia GeForce GTX 1080 Ti |
|---|---|
| вид спереди | |
 |
 |
| вид сзади | |
 |
 |
PCB у карт двух поколений сильно различаются. Обе имеют 352-битную шину обмена с памятью, но микросхемы памяти размещены по-разному (в силу разных типов памяти). Также на обеих разведена шина обмена в 384 бит (PCB рассчитаны на монтаж 12 микросхем памяти суммарным объемом в 12 ГБ, просто одна микросхема не установлена).
Схема питания построена на базе 13-фазного цифрового преобразователя iMON DrMOS. Эта динамическая система управления питанием способна осуществлять мониторинг тока чаще раза в миллисекунду, что дает жесткий контроль над поступающим на ядро питанием. Это помогает GPU дольше работать на повышенных частотах.
Через утилиту EVGA Precision X1 можно не только повысить частоты работы, но и запустить Nvidia Scanner, который поможет определить безопасный максимум работы ядра и памяти, то есть самый быстрый режим работы в 3D. По причине очень сжатых сроков тестирования мы разгоном попавшей к нам в руки видеокарты не занимались, но обещаем вернуться к теме разгона при рассмотрении серийных карт на базе RTX 2080 Ti.
Еще следует отметить, что карта оснащается новым разъемом USB-C (VirtualLink) специально для работы с устройствами виртуальной реальности следующего поколения.
Охлаждение и нагрев


Главной частью кулера является большая испарительная камера, оборотная часть которой припаяна к массивному радиатору. Поверх установлен кожух с двумя вентиляторами, работающими на одинаковой частоте вращения. Микросхемы памяти и силовые транзисторы охлаждаются специальной пластиной, также жестко соединенной с основным радиатором. С оборотной стороны карта прикрывается специальной пластиной, которая обеспечивает не только жесткость печатной платы, но и дополнительное охлаждение через специальный термоинтерфейс в местах монтажа микросхем памяти и силовых элементов.
Мониторинг температурного режима с помощью MSI Afterburner (автор А. Николайчук AKA Unwinder):
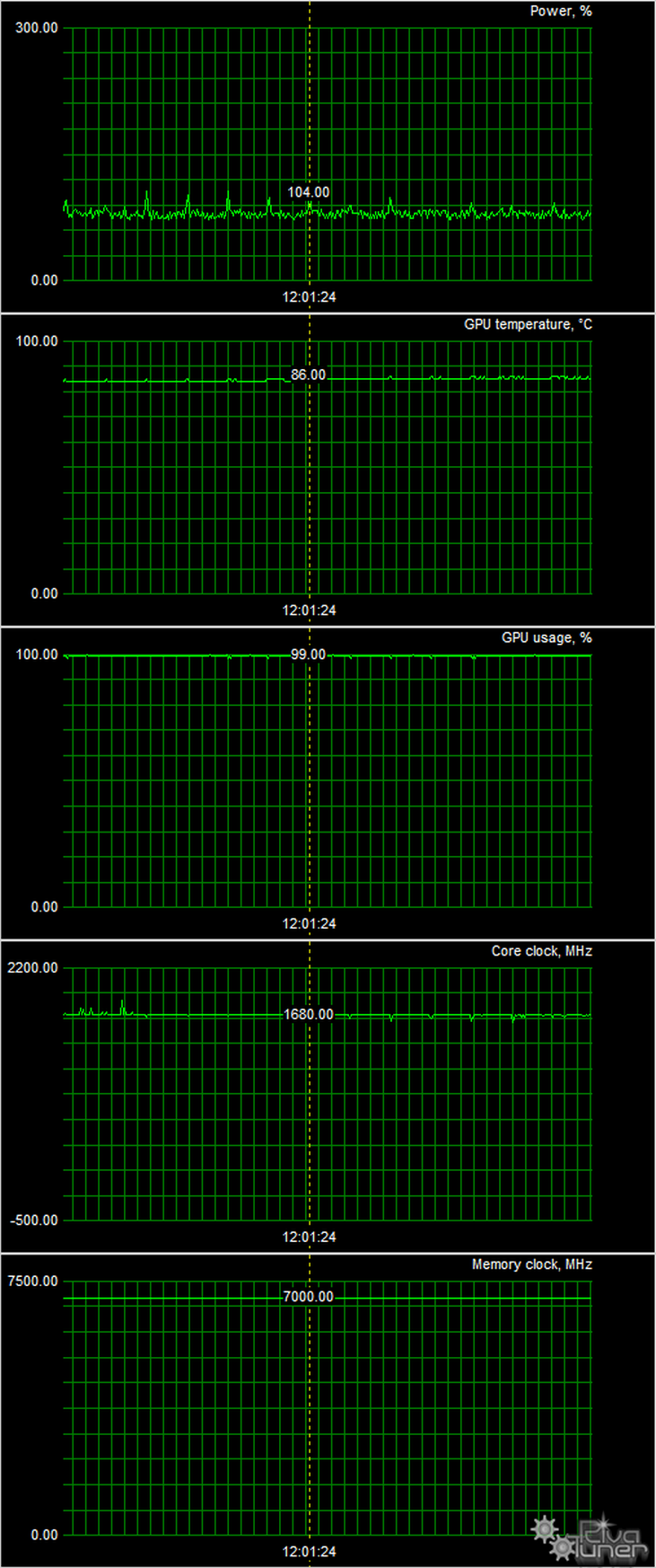
После 6-часового прогона под нагрузкой максимальная температура ядра не превысила 86 градусов, что является отличным результатом для видеокарты самого топового уровня.
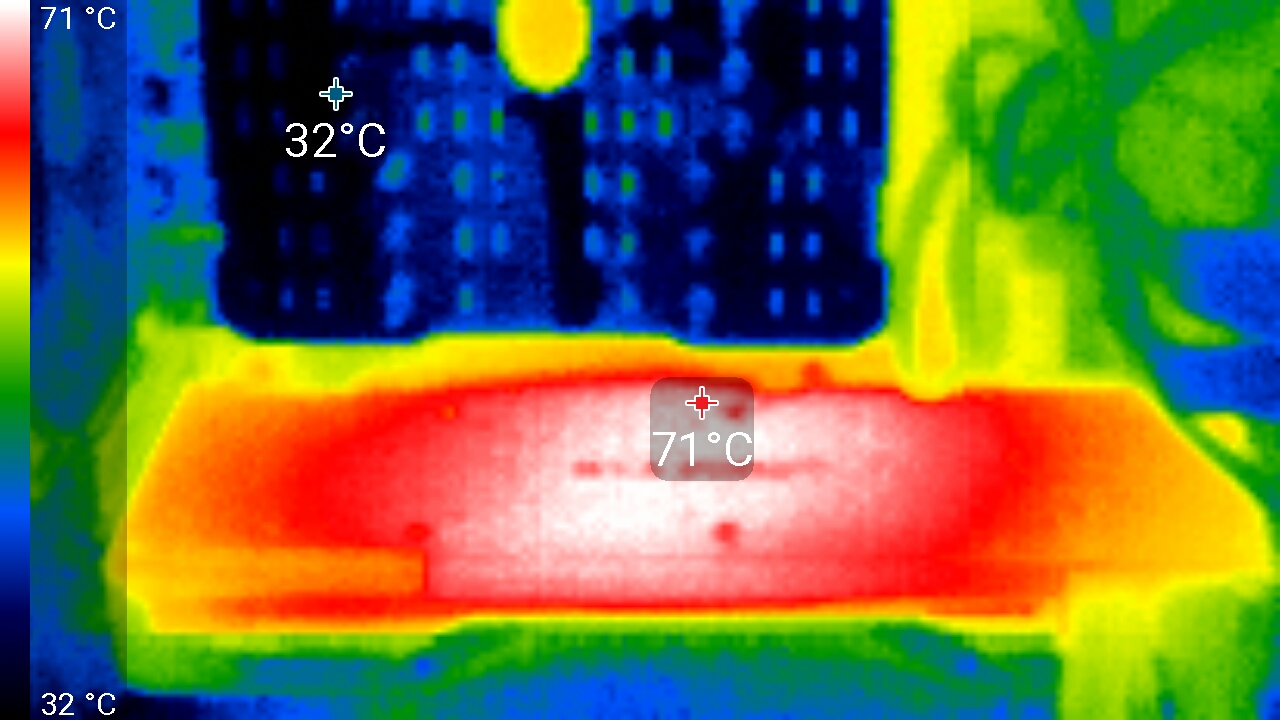
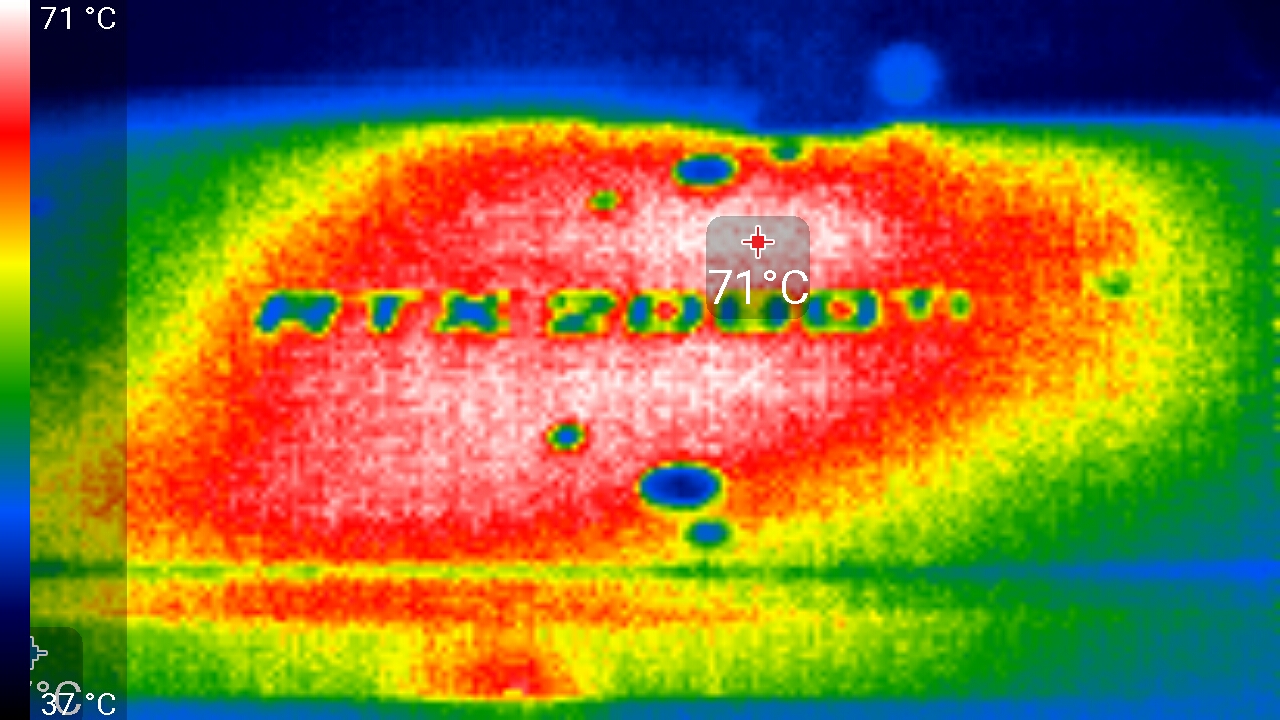
Максимальный нагрев — центральная область с обратной стороны печатной платы.
Шум
Методика измерения шума подразумевает, что помещение шумоизолировано и заглушено, снижены реверберации. Системный блок, в котором исследуется шум видеокарт, не имеет вентиляторов, не является источником механического шума. Фоновый уровень 18 дБА — это уровень шума в комнате и уровень шумов собственно шумомера. Измерения проводятся с расстояния 50 см от видеокарты на уровне системы охлаждения.
Режимы измерения:
- Режим простоя в 2D: загружен интернет-браузер с сайтом iXBT.com, окно Microsoft Word, ряд интернет-коммуникаторов
- Режим 2D с просмотром фильмов: используется SmoothVideo Project (SVP) — аппаратное декодирование со вставкой промежуточных кадров
- Режим 3D с максимальной нагрузкой на ускоритель: используется тест FurMark
Оценка градаций уровня шума выполняется по методике, описанной здесь:
- 28 дБА и менее: шум плохо различим уже на расстоянии одного метра от источника, даже при очень низком уровне фонового шума. Оценка: шум минимальный.
- от 29 до 34 дБА: шум различим уже с двух метров от источника, но не особо обращает на себя внимания. С таким уровнем шума вполне можно мириться даже при долговременной работе. Оценка: шум низкий.
- от 35 до 39 дБА: шум уверенно различается и заметно обращает на себя внимание, особенно в помещении с низким уровнем шума. Работать с таким уровнем шума можно, но спать будет затруднительно. Оценка: шум средний.
- 40 дБА и более: такой постоянный уровень шума уже начинает раздражать, от него быстро устаешь, появляется желание выйти из комнаты или выключить прибор. Оценка: шум высокий.
В режиме простоя в 2D температура составляла 34 °C, вентиляторы вращались на частоте примерно 1500 оборотов в минуту. Шум был равен 26,1 дБА.
При просмотре фильма с аппаратным декодированием ничего не менялось — ни температура ядра, ни частота вращения вентиляторов. Разумеется, уровень шума тоже оставался прежним (26,1 дБА).
В режиме максимальной нагрузки в 3D температура достигала 86 °C. Вентиляторы при этом раскручивались до 2400 оборотов в минуту, шум вырастал до 39,0 дБА, так что данную СО можно назвать шумной, но не экстремально шумной.
Комплект поставки и упаковка
Базовый комплект поставки серийной карты должен включать в себя руководство пользователя, диск с драйверами и утилитами. С нашей референсной картой в комплекте шли лишь руководство пользователя и переходник DP-to-DVI.

Синтетические тесты
Начиная с этого обзора, мы обновили пакет синтетических тестов, но он еще экспериментальный, не устоявшийся. Так, мы бы хотели добавить больше примеров с вычислениями (compute shaders), но один из распространенных бенчмарков CompuBench просто не заработал на GeForce RTX 2080 Ti — вероятно, виновата «сырость» драйверов. В будущем мы постараемся расширить и улучшить набор синтетических тестов. Если у читателей есть четкие и обоснованные предложения — пишите их в комментариях к статье.
Из ранее использовавшихся тестов RightMark3D 2.0 мы оставили лишь несколько самых тяжелых тестов. Остальные уже изрядно устарели и на столь мощных GPU упираются в различные ограничители, не загружают работой блоки графического процессора и не показывают истинную его производительность. А вот синтетические Feature-тесты из набора 3DMark Vantage мы пока что оставили в полном составе, так как заменить их попросту нечем, хотя и они уже устарели.
Из более новых бенчмарков мы начали использовать несколько примеров, входящих в DirectX SDK и пакет SDK компании AMD (скомпилированные примеры применения D3D11 и D3D12), а также несколько тестов для измерения производительности трассировки лучей и один временный тест для сравнения производительности сглаживания методами DLSS и TAA. В качестве полусинтетического теста у нас также будет 3DMark Time Spy, помогающий определить пользу от асинхронных вычислений.
Синтетические тесты проводились на следующих видеокартах (набор для каждого бенчмарка свой):
- GeForce RTX 2080 Ti со стандартными параметрами (сокращенно RTX 2080 Ti)
- GeForce GTX 1080 Ti со стандартными параметрами (сокращенно GTX 1080 Ti)
- GeForce GTX 980 Ti со стандартными параметрами (сокращенно GTX 980 Ti)
- Radeon RX Vega 64 со стандартными параметрами (сокращенно RX Vega 64)
- Radeon RX 580 со стандартными параметрами (сокращенно RX 580)
Для анализа производительности видеокарты GeForce RTX 2080 Ti мы взяли именно эти решения по следующим причинам. GeForce GTX 1080 Ti является прямым предшественником новинки, основанным на аналогичном по позиционированию графическом процессоре из предыдущего поколения Pascal. Видеокарта GeForce GTX 980 Ti олицетворяет топовое же позапрошлое поколение Maxwell — посмотрим, как росла производительность наиболее производительных чипов Nvidia из поколения в поколение.
У конкурирующей компании AMD выбрать что-то было непросто — у них нет конкурентоспособных продуктов, способных выступать на уровне GeForce RTX 2080 Ti, и таковых пока что не видно даже на горизонте. В итоге мы остановились на паре видеокарт разных семейств и позиционирования, хоть ни одна из них и не может быть соперником для GeForce RTX 2080 Ti. Впрочем, видеокарта Radeon RX Vega 64 в любом случае является наиболее производительным решением компании AMD, а RX 580 взята просто для поддержки и присутствует лишь в самых простых тестах.
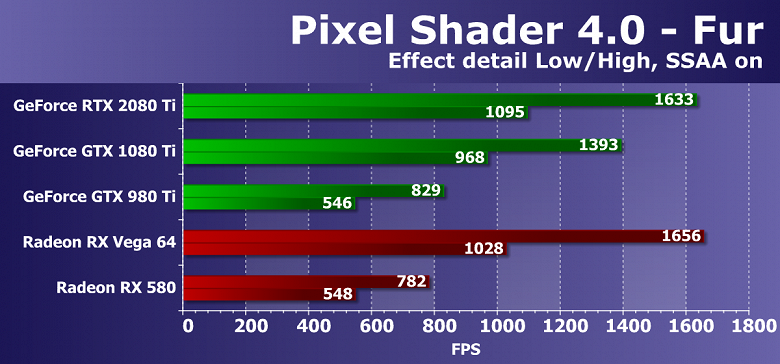
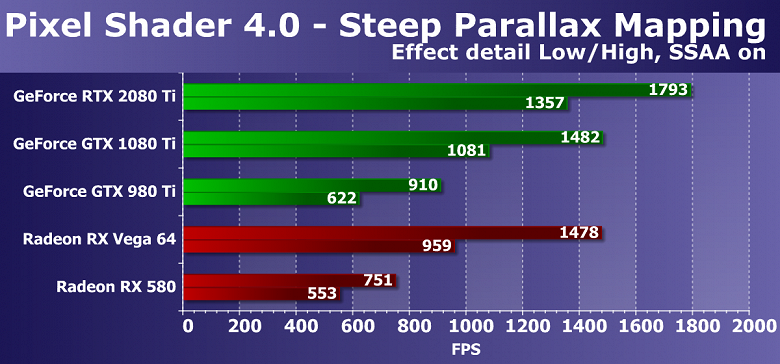







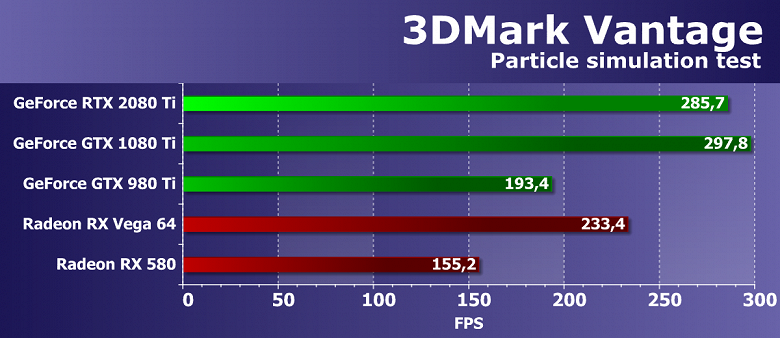
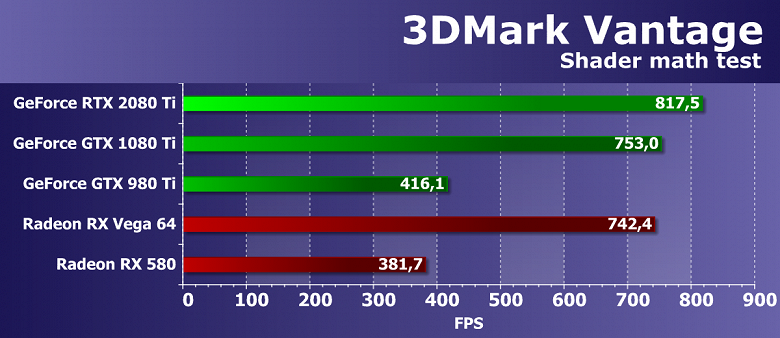


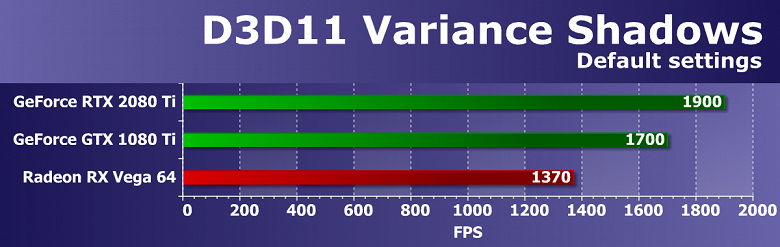


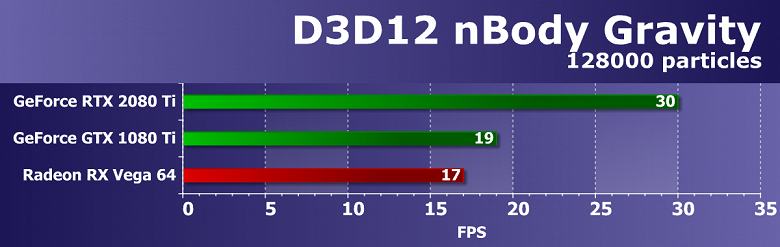

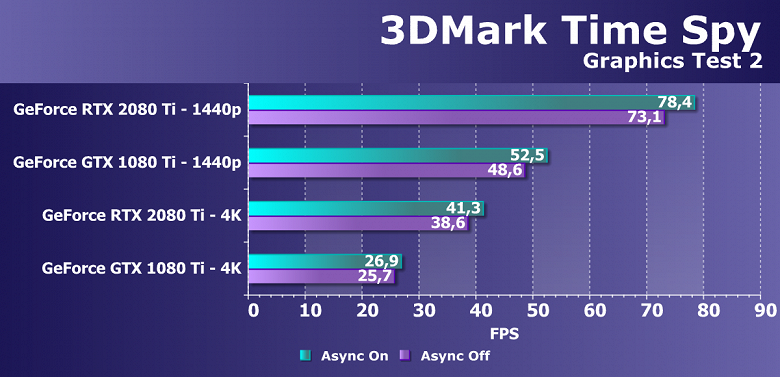
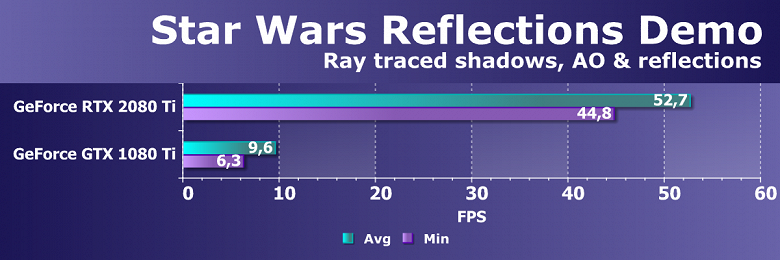
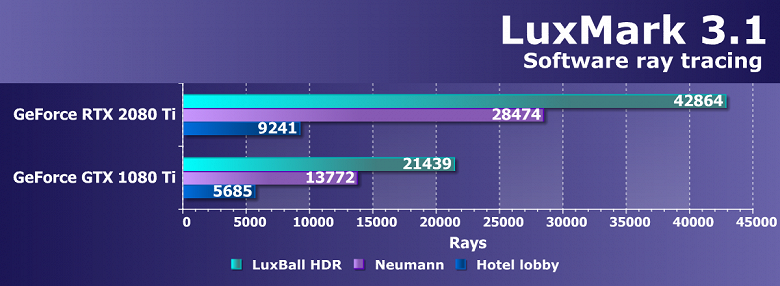


Выводы по синтетическим тестам
Судя по всему, новая видеокарта Nvidia GeForce RTX 2080 Ti, основанная на мощнейшем графическом процессоре TU102 с архитектурой Turing, станет наиболее производительным решением на рынке игровых видеокарт, несмотря на спорные результаты в некоторых бенчмарках. Нужно признать, что не все так радужно у новинки с синтетическими тестами, особенно старыми. Вполне возможно, что в некоторых существующих играх тоже не будет заметно влияние улучшений в вычислительных блоках, а так как их количество возросло по сравнению с Pascal не так уж и сильно, то и приросту в скорости в таких случаях взяться особо неоткуда. Именно поэтому в немалой части старых синтетических тестов GeForce RTX 2080 Ti обгоняет GTX 1080 Ti вовсе не с тем преимуществом, которое обычно ожидается от нового поколения GPU.
С другой стороны, нам совершенно понятно, что в этом поколении GPU компания Nvidia сделала ставку на абсолютно новые типы исполнительных блоков, добавив специализированные RT-ядра и тензорные ядра для ускорения трассировки лучей и задач искусственного интеллекта. Пока что в играх эти технологии практически не применяются, так что они не способны обеспечить преимущество семейству Turing прямо сейчас, но в будущем и поддержка трассировки лучей появится в большем количестве игр, и то же сглаживание методом DLSS явно получит более широкое распространение. И вот в этих задачах новинка уже весьма хороша, как показали наши тесты трассировки лучей и DLSS-тест в Final Fantasy XV.
В любом случае, новая топовая видеокарта компании Nvidia показала отличные результаты во многих синтетических тестах, выступив недостаточно уверенно лишь в некоторых из них. Но синтетику всегда нужно переносить на игры с определенным пониманием, которое говорит нам о том, что у GeForce RTX 2080 Ti есть и очень сильные, и относительно слабые стороны. В игровых приложениях все будет несколько иначе по сравнению с синтетическими тестами, и GeForce RTX 2080 Ti должна показать даже в существующих играх достаточно высокую скорость при отсутствии упора в CPU, хотя прирост по сравнению с GTX 1080 Ti может порадовать нас далеко не всегда.
Игровые тесты
Конфигурация тестового стенда
- Компьютер на базе процессора AMD Ryzen 7 1800X (Socket AM4):
- процессор AMD Ryzen 7 1800X (o/c 4 ГГц);
- СО Antec Kuhler H2O 920;
- системная плата Asus ROG Crosshair VI Hero на чипсете AMD X370;
- оперативная память 16 ГБ (2×8 ГБ) DDR4 AMD Radeon R9 UDIMM 3200 МГц (16-18-18-39);
- жесткий диск Seagate Barracuda 7200.14 3 ТБ SATA2;
- блок питания Seasonic Prime 1000 W Titanium (1000 Вт);
- операционная система Windows 10 Pro 64-битная; DirectX 12;
- монитор Asus PG27UQ (27″);
- драйверы AMD версии Adrenalin Edition 18.9.1;
- драйверы Nvidia версии 399.24 (для RTX 2080 Ti — 411.51);
- VSync отключен.
Список инструментов тестирования
Во всех играх использовалось максимальное качество графики в настройках.
- Wolfenstein II: The New Colossus (Bethesda Softworks/MachineGames)
- Tom Clancy’s Ghost Recon Wildlands (Ubisoft/Ubisoft)
- Assassin’ Creed: Origins (Ubisoft/Ubisoft)
- BattleField 1 (EA Digital Illusions CE/Electronic Arts)
- Far Cry 5 (Ubisoft/Ubisoft)
- Shadow Of The Tomb Raider (Eidos Montreal/Square Enix) — HDR включен
- Total War: Warhammer II (Creative Assembly/Sega)
- Ashes Of The Singularity (Oxide Games, Stardock Entertainment/Stardock Entertainment)
Следует отметить, что в самой новой игре Shadow Of The Tomb Raider мы использовали HDR как ключевое расширение функциональности. Исследование показало, что активация HDR оказывает незначительное действие на производительность. Визуально же мы можем увидеть некоторые отличия.








Ну и, собственно, сами тесты.



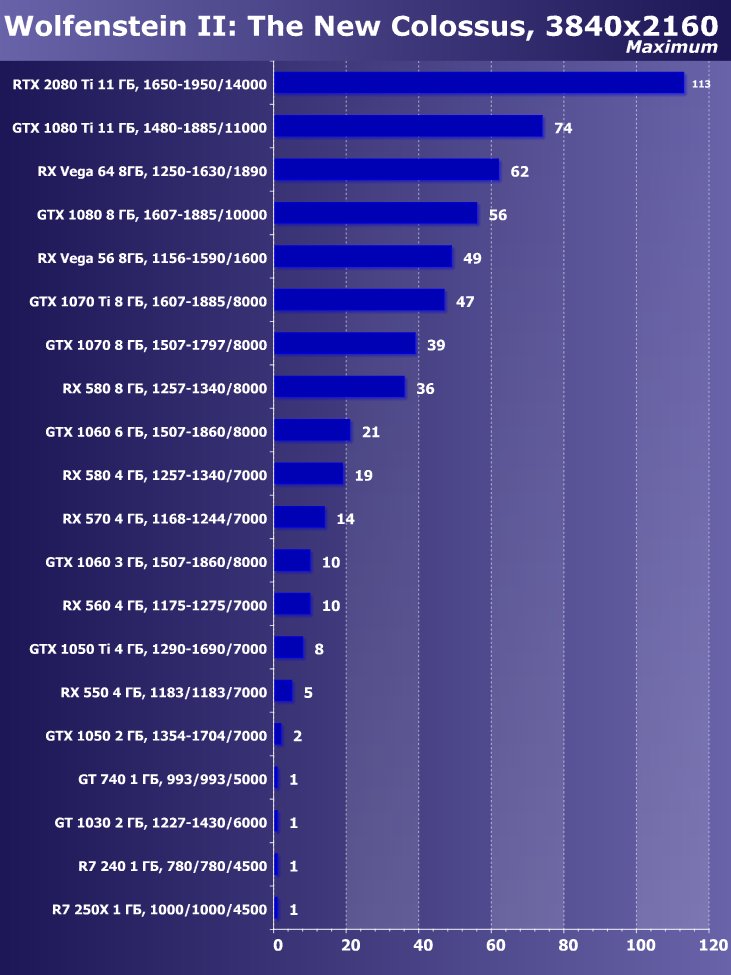

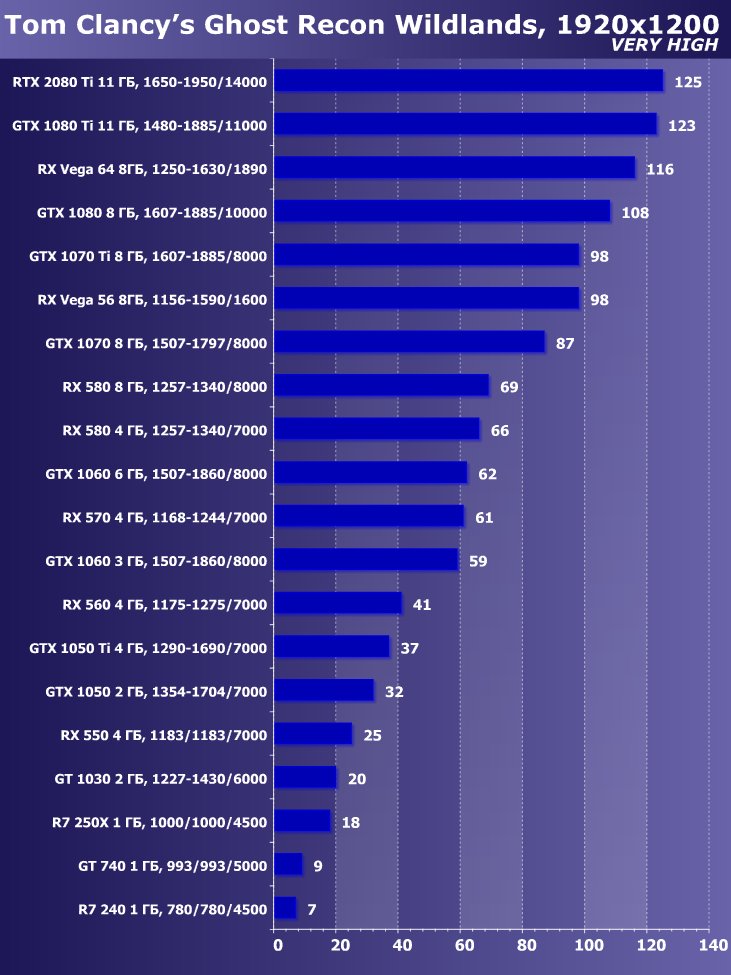

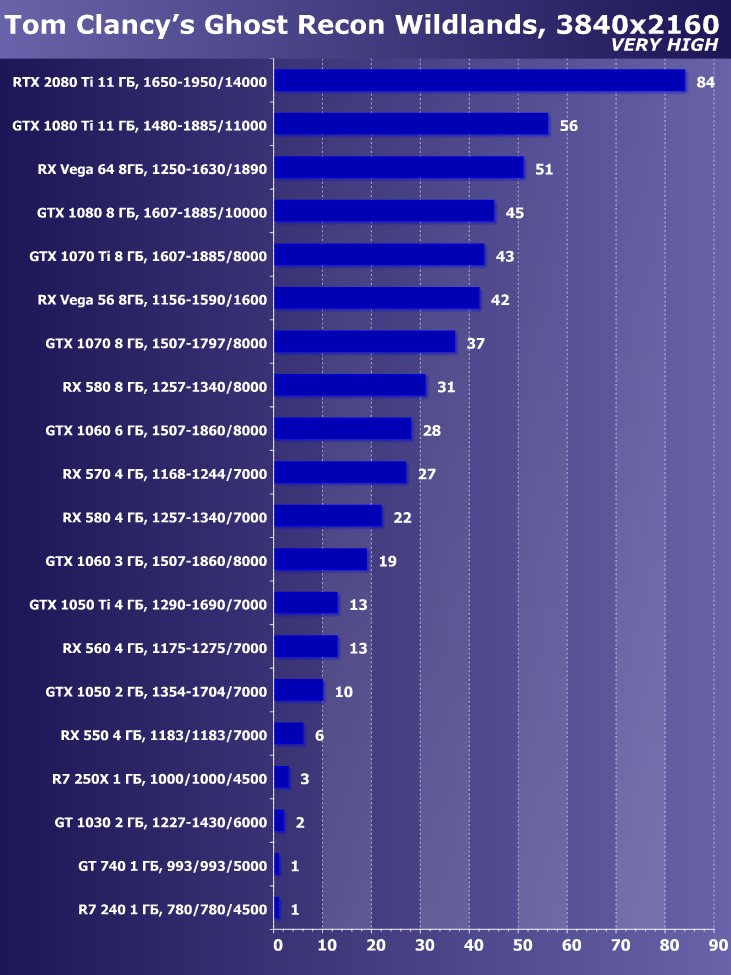


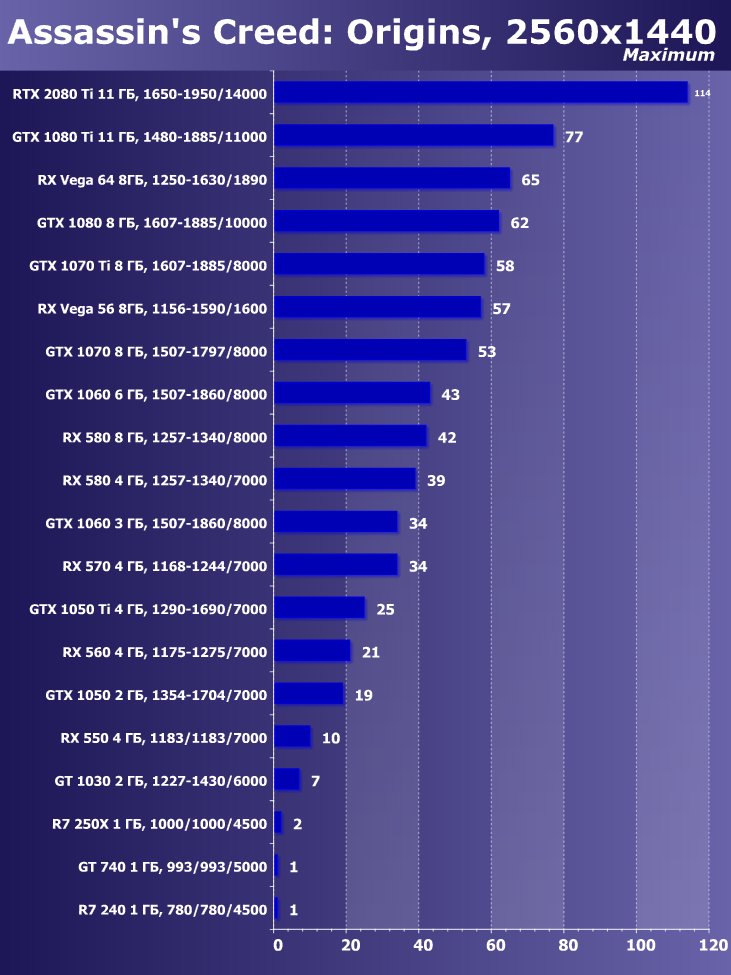




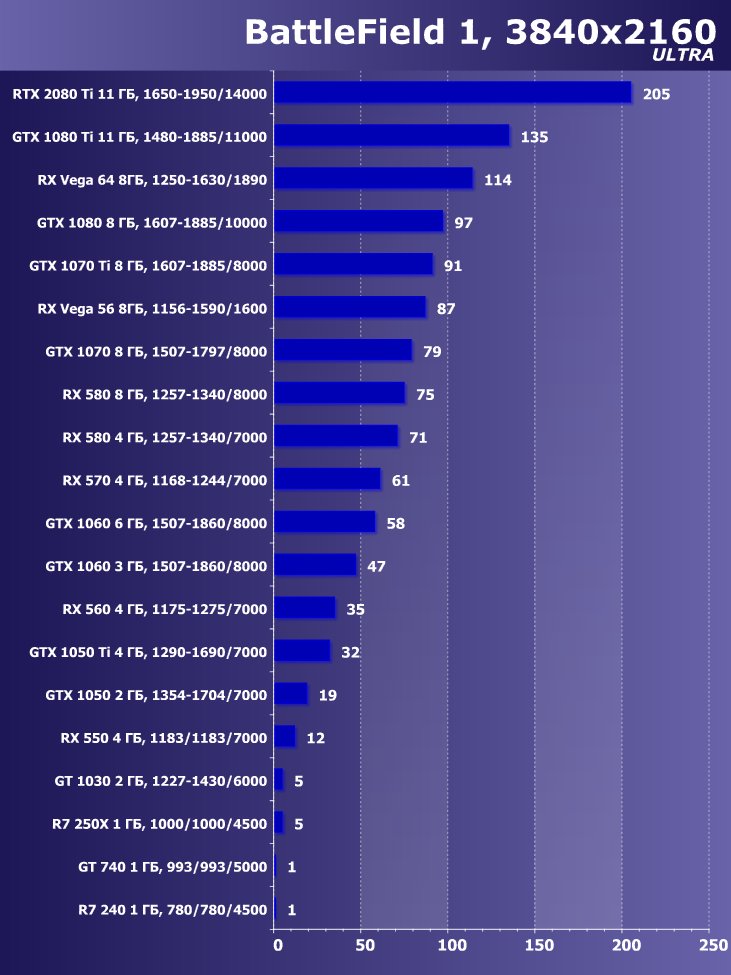



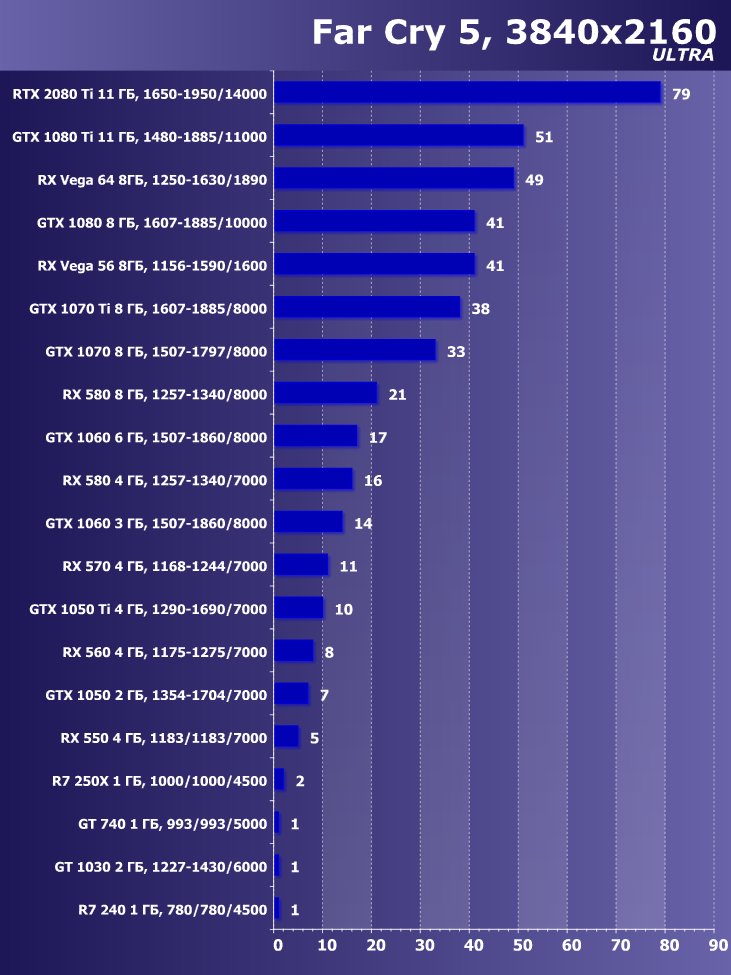

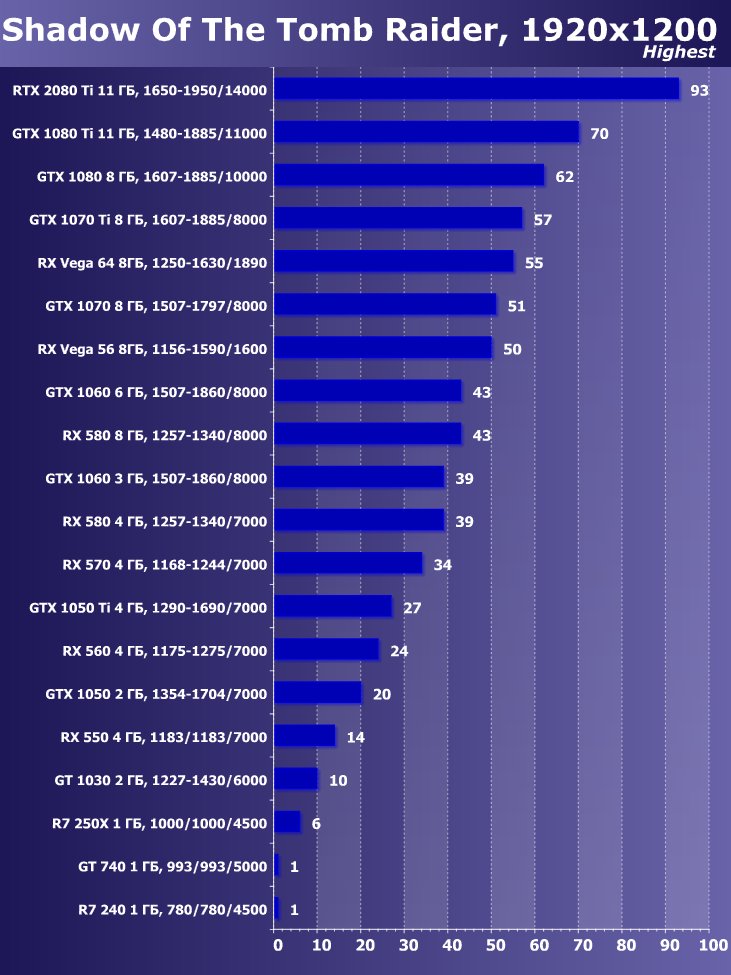
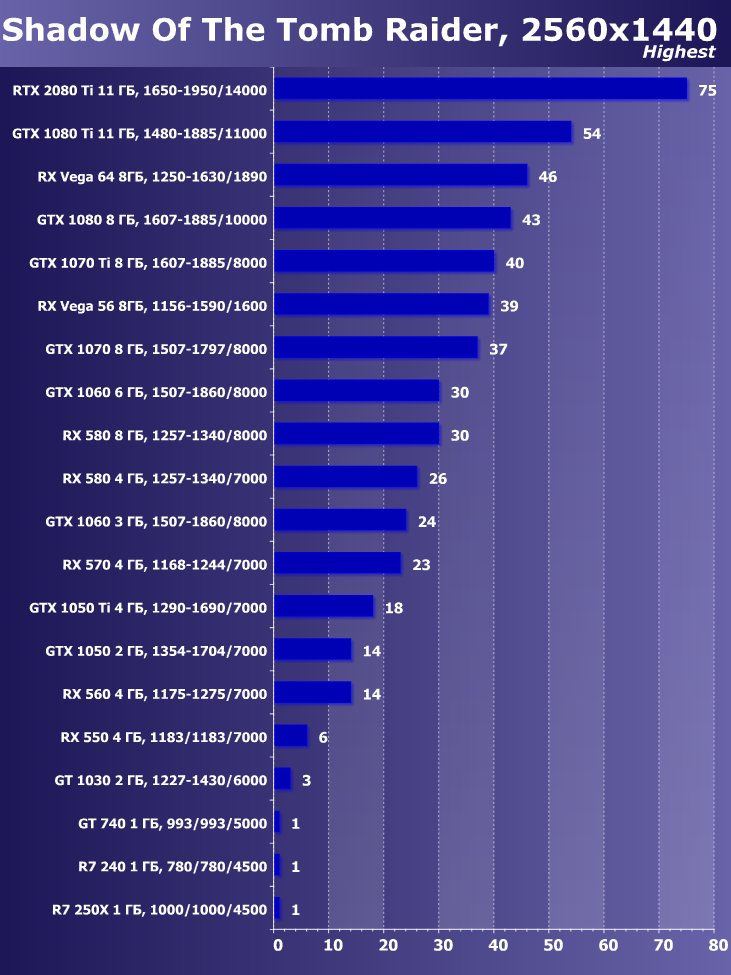
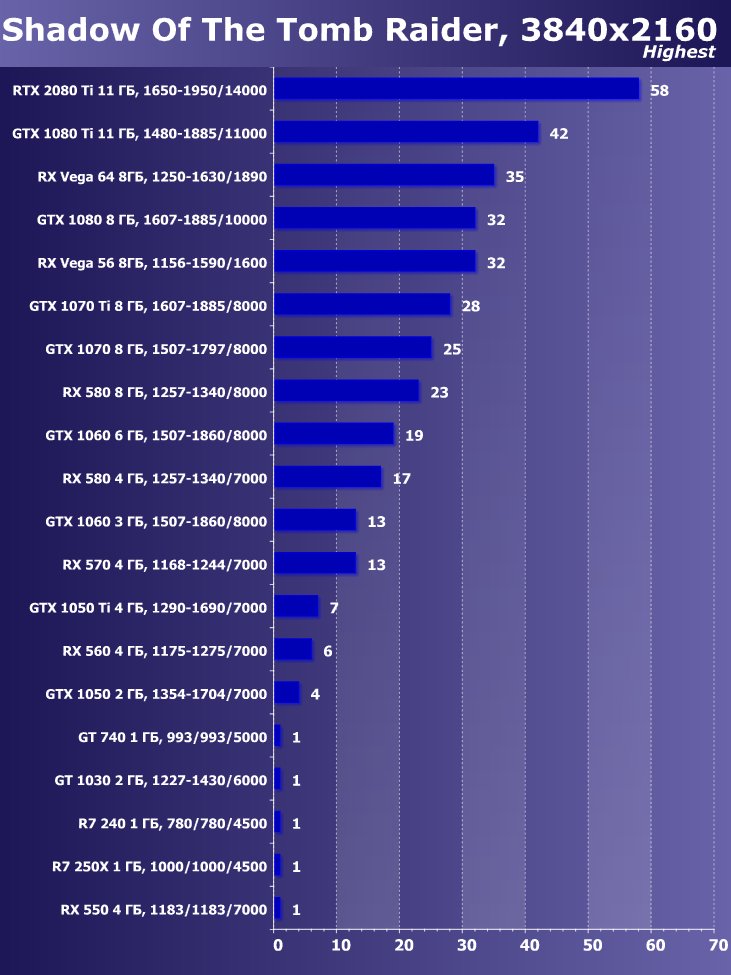


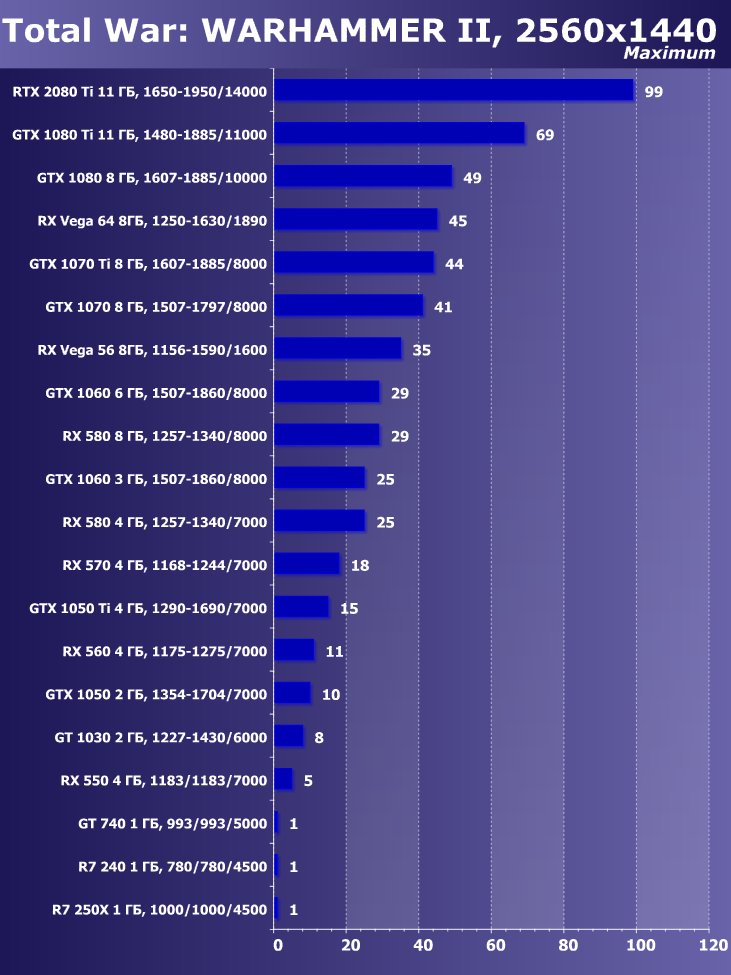
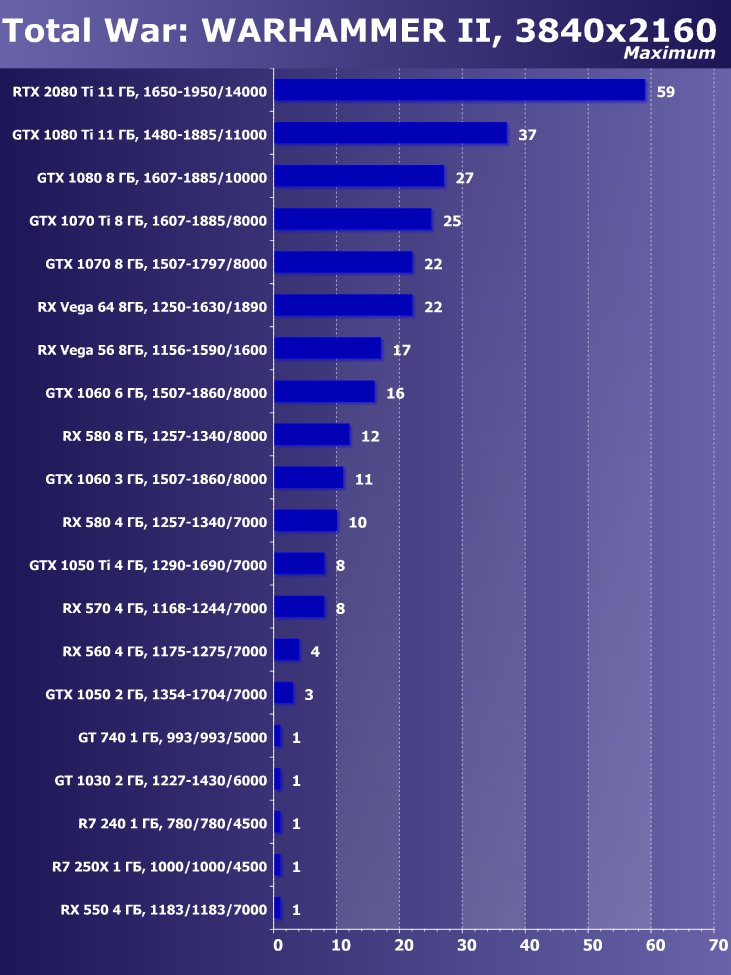

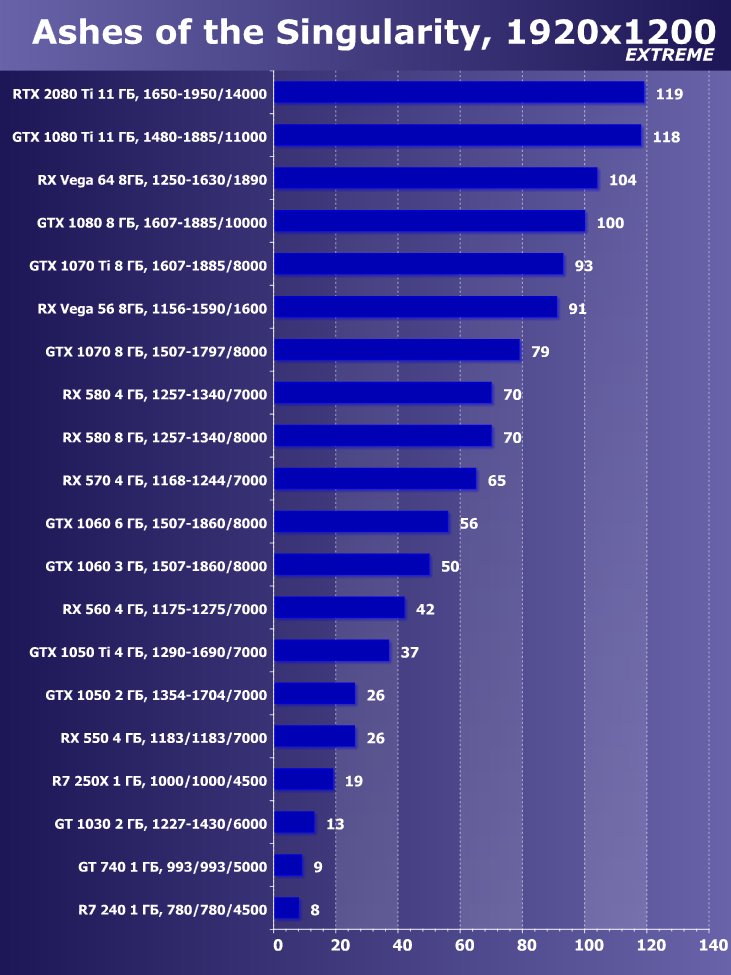

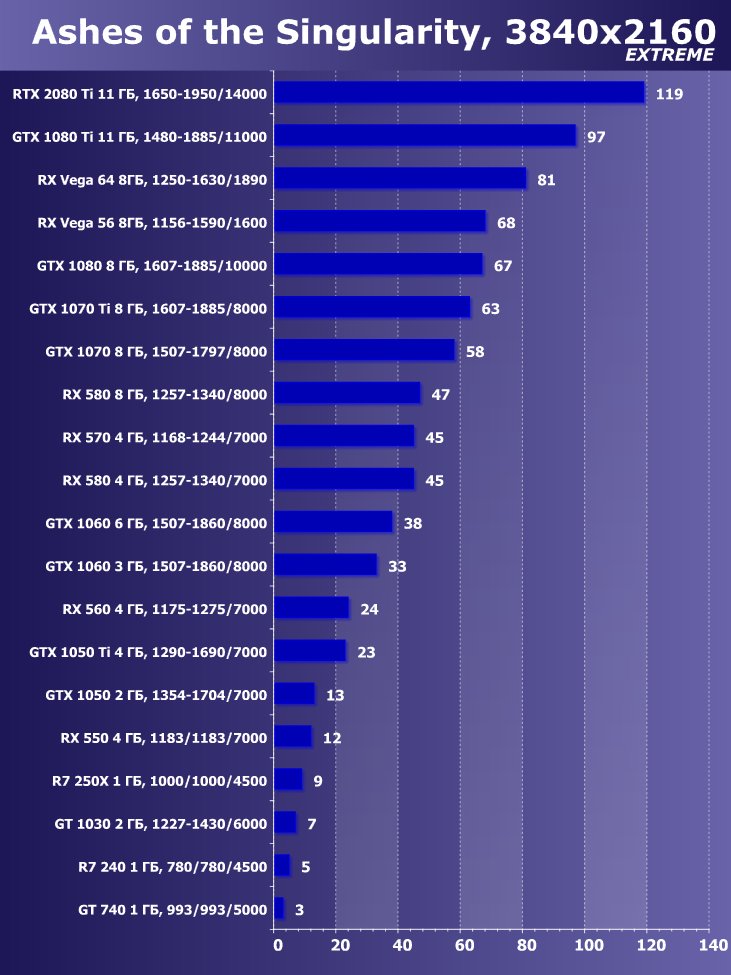
Рейтинг iXBT.com
Рейтинг ускорителей iXBT.com демонстрирует нам функциональность видеокарт друг относительно друга и нормирован по самому слабому ускорителю — GeForce GT 740 (то есть сочетание скорости и функций GT 740 приняты за 100%). Рейтинги ведутся по 20 ежемесячно исследуемым нами акселераторам в рамках проекта Лучшей видеокарты месяца. Из общего списка выбирается группа карт для анализа, куда входят RTX 2080 Ti и его конкуренты. Для расчета рейтинга полезности использованы розничные цены на середину сентября 2018 года (для RTX 2080 Ti использована рекомендованная розничная цена).
| № | Модель ускорителя | Рейтинг iXBT.com | Рейтинг полезности | Цена, руб. |
|---|---|---|---|---|
| 01 | RTX 2080 Ti 11 ГБ, 1650—1950/14000 | 3890 | 432 | 90 000 |
| 02 | GTX 1080 Ti 11 ГБ, 1480—1885/11000 | 3170 | 616 | 51 500 |
| 03 | RX Vega 64 8ГБ, 1250—1630/1890 | 2760 | 600 | 46 000 |
Преимущество новинки очевидно ,в среднем по всем играм и разрешениям прирост относительно GTX 1080 Ti получился 22,7%, а относительно RX Vega 64 — 40,9%. Однако надо понимать, что ускоритель такого уровня рассчитан на использование в максимально возможных на сегодня массовых разрешениях, то есть как минимум в 4К, а в нем прирост RTX 2080 Ti относительно GTX 1080 Ti в среднем уже выше 45%, а относительно RX Vega 64 он составляет все 60%.
Рейтинг полезности
Рейтинг полезности тех же карт получается, если показатели предыдущего рейтинга разделить на цены соответствующих ускорителей. Для ускорителей топового уровня этот рейтинг не очень показателен, такие карты не выпускаются массовыми тиражами и нацелены прежде всего на энтузиастов, а в рейтинге полезности их на голову обходят середняки и иногда даже чуть ли не бюджетные решения.
| № | Модель ускорителя | Рейтинг полезности | Рейтинг iXBT.com | Цена, руб. |
|---|---|---|---|---|
| 12 | GTX 1080 Ti 11 ГБ, 1480—1885/11000 | 616 | 3170 | 51 500 |
| 13 | RX Vega 64 8ГБ, 1250—1630/1890 | 600 | 2760 | 46 000 |
| 18 | RTX 2080 Ti 11 ГБ, 1650—1950/14000 | 432 | 3890 | 90 000 |
Полагаем, что и тут комментарии излишни.
Выводы
Nvidia GeForce RTX 2080 Ti на сегодня не только самый быстрый в мире ускоритель игрового класса, но и самый высокотехнологичный. Чтобы сравнить его с решениями предыдущего поколения, простых тестов в 3D-играх недостаточно. Если бы это был GTX 2080 Ti, то мы бы восхитились приростом производительности в старших разрешениях, расстроились из-за стартовых цен новинок — да и разошлись бы.
Однако перед нами не GTX, а RTX! Это три года работы большого коллектива над новой архитектурой, это снова позиция у руля технологий (как во времена GeForce256 в 1999 году), это очередной двигатель прогресса в 3D-играх, потому что в конце концов трассировка лучей принесет то самое улучшение графики, которого мы ждем уже не то что годами, а десятилетиями. Разумеется, новые технологии Nvidia годятся не только для игр, им есть применение и в сфере вычислений и профессиональной графики. Однако перед нами именно GeForce, а не Titan или что-то еще. А серия GeForce — это прежде всего игры. Поэтому сегодняшний материал особо интересен, ведь новшества реально помогают (во всяком случае, помогут в ближайшем будущем) разработчикам сделать игры более захватывающими в плане графики (хотя мне было достаточно походить в Shadow Of The Tomb Raider с включенным HDR, чтобы ощутить примерно такой же детский и искренний восторг от картинки, сцен, среды, какой я когда-то получил от первого Far Cry, если кто еще помнит ту первую игру с открытым пространством и шикарными тропическими пейзажами).
Если спуститься «на землю», то объявленная цена на новый ускоритель (и на всю серию RTX 2000) многих очень неприятно удивила, потому что уже много лет соблюдалась традиция: цены новых премиальных видеокарт плюс-минус равнялись начальным ценам предыдущих флагманов. Сейчас уже только ленивый не попинал Nvidia за «жадность» или за «беспардонное использование временно сложившейся монополии на рынке топовых 3D-карт». Да, к сожалению, компания AMD пока взяла тайм-аут в области дискретной графики, и следующие их решения ожидаются не ранее 2019 года (возможно, даже во второй половине), так что у Nvidia в принципе нет ограничителя в виде цен на конкурирующие продукты. Однако тут палка о двух концах. С одной стороны, надо максимально быстро «отбить» многомиллионные затраты на разработку Turing, ведь на сегодня этот проект принес лишь убытки, а продажи должны вывести его на прибыльность. С другой стороны, если заломить цены еще выше, то можно лишиться не только покупателей (они предпочтут искать GTX 1080 Ti, особенно на вторичном рынке), но и интереса разработчиков/издателей игр, которые тщательно следят за распространением новых видеокарт (какой смысл реализовывать новые технологии в играх, если мало кто сможет воспользоваться ими по причине скудной распространенности соответствующих 3D-ускорителей?). Вероятно, в Nvidia выбрали нечто среднее: поднять цены, чтобы побыстрее окупить затраты на Turing, но не поднимать их запредельно, чтобы любители 3D-игр на ПК все же смогли купить если и не RTX 2080 Ti, то RTX 2080 или RTX 2070. Плюс, нельзя забывать, что мечтания производителей жестко контролируются рынком, то есть нашим с вами спросом. Не будут покупать RTX 2080 Ti за 90 тысяч рублей (или по 1000-1200 долларов на Западе) — значит, Nvidia будет вынуждена снижать цены. Правило универсальное.
Так что желающим повозмущаться ценовой политикой можем лишь посоветовать просто подождать. По мере появления карт, по мере насыщения ими страты энтузиастов и любителей всего самого крутого и быстрого цены начнут идти вниз. Это закон рынка.
Итак, что мы имеем: RTX 2080 Ti демонстрирует серьезный прирост производительности в старших разрешениях даже в обычных (без HDR/RT) играх относительно былого флагмана GTX 1080 Ti (не говоря уж о самом быстром на сегодня продукте AMD — Radeon RX Vega64: тот отстает совсем уж радикально). Великолепный новый антиалиасинг DLSS продемонстрировал свое преимущество и по скорости, и по качеству. Плюс есть огромный задел для использования разработчиками игр технологии трассировки лучей, а также ИИ с помощью тензорных ядер (наглядный пример такой реализации — как раз DLSS). Новый ускоритель предлагает обновленный интерфейс VirtualLink для связи с устройствам виртуальной реальности нового поколения (VR никуда не делся, не умер, просто ожидается очередной скачок технологий). Если найдутся фанаты, которым будет мало даже такого ускорителя, они могут купить два и соединить их в SLI (тогда производительность в разрешении 4К должна стать просто сказочной).
Также отрадно видеть обновленный референс-дизайн карты, и вообще мы поздравляем Nvidia с выпуском этой версии Founder’s Edition. Не секрет, что компания решила более активно выводить на рынок карты под своим собственным брендом, создавая, по сути, конкуренцию своим партнерам. И не следует забывать про мечту оверклокеров средней руки (матерых, стремящихся к установке рекордов с жидким азотом и помиранием «железа», мы не считаем) — Nvidia Scanner. Технология простая, как апельсин: нажал на кнопку — и жди, оно само покрутит колесики и выдаст вам максимум скорости, ну а счет за электричество придет позже (шутка).
Выше: Nvidia GeForce RTX 2080 Ti с трассировкой лучей, тензорное ядро учитывает ветер (направление движения струй) с прогнозом, ядро самообучаемое. (Тоже шутка :)
В номинации «Оригинальный дизайн» карта Nvidia GeForce RTX 2080 Ti (Founder’s Edition) получила награду:

Благодарим компанию Nvidia Russia
и лично Ирину Шеховцову
за предоставленную на тестирование видеокарту
Также благодарим компанию Asus Russia
за предоставленный для тестирования 27-дюймовый геймерский монитор Asus ROG Swift PG27UQ формата 4K/UltraHD с IPS-матрицей и высокой частотой обновления экрана (до 144 Гц). Благодаря технологии квантовых точек он обладает расширенным цветовым охватом (DCI-P3), а поддержка стандарта HDR означает повышенную контрастность, поэтому данный монитор выдает невероятно реалистичную картинку с насыщенными цветами. Для автоматического изменения яркости экрана в соответствии с окружающими условиями имеется встроенный датчик освещенности. Внешний вид устройства можно персонализировать с помощью синхронизируемой подсветки Aura и встроенных проекционных элементов.

Для тестового стенда:
блок питания Seasonic Prime 1000 W Titanium предоставлен компанией Seasonic
модули памяти AMD Radeon R9 8 ГБ UDIMM 3200 МГц и системная плата Asus ROG Crosshair VI Hero предоставлены компанией AMD
монитор Dell UltraSharp U3011 предоставлен компанией Юлмарт

