Семейство RADEON R520, RV530 и RV515, теоретическая часть обзора

"Легким движением руки, брюки превращаются:"
Не секрет, что выход нового поколения ускорителей от ATI задержался. Был ли тому причиной новый процесс (90 нм) и попытки сделать ревизию R520 обеспечивающую необходимые частоты и процент выхода годных кристаллов, или иные соображения (например вынужденное затишье на графическом рынке в плане новшеств, перед выходом Vista и ускорителей соответствующих прадигме WGF 2.0), но факт остается фактом, конкурирующий продукт от NVIDIA появился раньше и мы уже успели с ним подробно познакомиться, сделав четкий вывод о эволюционном а не революционном характере G70 по отношению к семейству NV4X. Здесь, как мы уже знаем (в том числе из нашего предварительного материала) ситуация несколько иная: в наличии и другой тех-процесс и другая архитектура. Семейство состоит из трех новых ускорителей — производительного R520, среднего RV530 и экономичного RV515. Встречайте, шейдеры 3.0 в исполнении ATI — сделано со знаком качества.
Официальные спецификации RADEON X1800
- Кодовое имя чипа R520
- Технология 90 нм
- 305 миллиона транзисторов (у G70 — 302)
- FС корпус (flip-chip, перевернутый чип без металлической крышки)
- 256 бит интерфейс памяти
- До 1 гигабайта GDDR-3 памяти
- PCI Express 16х шинный интерфейс
- 16 пиксельных процессоров
- 16 текстурных блоков
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- 8 вершинных процессоров
- Сквозная точность вычислений — FP32 (и вершины и пиксели)
- Полная поддержка SM 3.0 (шейдеры версии 3.0) включая динамические ветвления в пиксельных и вершинных процессорах, выбор значений текстур из вершинных процессоров и т.д.
- Эффективная реализация переходов и ветвлений
- Сквозная поддержка FP16 формата: произвольная фильтрация целочисленных и плавающих FP16 текстур (в том числе анизотропия), полностью поддерживается вывод в буфер кадра в плавающем формате FP16 (включая любые операции блендинга и даже MSAA). Сжатие FP16 текстур включая 3Dc.
- Новый RGBA (10:10:10:2) целочисленный тип данных в буфере кадра для более качественного рендеринга без привлечения FP16.
- Новый качественный алгоритм анизотропной фильтрации (пользователю доступен выбор между более быстрой и более качественной реализацией анизотропии), улучшена трилинейная фильтрация
- Поддержка "двустороннего" буфера шаблонов
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- Контроллер памяти с 512-битной внутренней кольцевой шиной (4 канала памяти, программируемый арбитраж).
- Эффективное кэширование и новая более эффективная реализация HyperZ
- 2xRAMDAC 400 МГц
- 2xDVI интерфейса c поддержкой HDCP, а также HDMI через переходник
- TV-Out и TV-In интерфейс, HDTV-Out
- Аппаратный видеопроцессор (для задач компрессии, декомпрессии и постобработки видео), новое поколение, способное ускорять работу с H.234 — новым алгоритмом компрессии видео, используемом в HD-DVD и Blu-Ray видео дисках.
- 2D ускоритель с поддержкой всех функций GDI+
- Поддержка технологии ATI CrossFire
Официальные спецификации RADEON X1600
- Кодовое имя чипа RV530
- Технология 90 нм
- ? миллиона транзисторов
- FС корпус (flip-chip, перевернутый чип без металлической крышки)
- 128 бит интерфейс памяти (возможна 64 бит конфигурация)
- До 512 мегабайт DDR1/2 или GDDR-3 памяти
- PCI Express 16х шинный интерфейс
- 12 пиксельных процессоров
- 4 текстурных блока (!)
- Вычисление, блендинг и запись до 4 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- 6 вершинных процессоров
- Сквозная точность вычислений — FP32 (и вершины и пиксели)
- Полная поддержка SM 3.0 (шейдеры версии 3.0) включая динамические ветвления в пиксельных и вершинных процессорах, выбор значений текстур из вершинных процессоров и т.д.
- Эффективная реализация переходов и ветвлений
- Сквозная поддержка FP16 формата: произвольная фильтрация целочисленных и плавающих FP16 текстур (в том числе анизотропия), полностью поддерживается вывод в буфер кадра в плавающем формате FP16 (включая любые операции блендинга и даже MSAA). Сжатие FP16 текстур включая 3Dc.
- Новый RGBA (10:10:10:2) целочисленный тип данных в буфере кадра для более качественного рендеринга без привлечения FP16.
- Новый качественный алгоритм анизотропной фильтрации (пользователю доступен выбор между более быстрой и более качественной реализацией анизотропии), улучшена трилинейная фильтрация
- Поддержка "двустороннего" буфера шаблонов MRT (Multiple Render Targets — рендеринг в несколько буферов)
- Контроллер памяти с 512-битной внутренней кольцевой шиной (4 канала памяти, программируемый арбитраж).
- Эффективное кэширование и новая более эффективная реализация HyperZ
- 2xRAMDAC 400 МГц
- 2xDVI интерфейса c поддержкой HDCP
- TV-Out и TV-In интерфейс, HDTV-Out Аппаратный видеопроцессор (для задач компрессии, декомпрессии и постобработки видео), новое поколение, способное ускорять работу с H.234 — новым алгоритмом компрессии видео, используемом в HD-DVD и Blu-Ray видео дисках.
- 2D ускоритель с поддержкой всех функций GDI+
- Поддержка технологии ATI CrossFire
Официальные спецификации RADEON X1300
- Кодовое имя чипа RV515
- Технология 90 нм
- ? миллиона транзисторов FС корпус (flip-chip, перевернутый чип без металлической крышки)
- 128 бит интерфейс памяти (возможны 64 и 32 бит конфигурации)
- До 256 мегабайт DDR1/2 или GDDR-3 памяти
- Поддержка технологии HyperMemory
- PCI Express 16х шинный интерфейс
- 4 пиксельных процессора (один квад)
- 4 текстурных блока
- Вычисление, блендинг и запись до 4 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- 3 вершинных процессора
- Сквозная точность вычислений — FP32 (и вершины и пиксели)
- Полная поддержка SM 3.0 (шейдеры версии 3.0) включая динамические ветвления в пиксельных и вершинных процессорах, выбор значений текстур из вершинных процессоров и т.д.
- Эффективная реализация переходов и ветвлений
- Сквозная поддержка FP16 формата: произвольная фильтрация целочисленных и плавающих FP16 текстур (в том числе анизотропия), полностью поддерживается вывод в буфер кадра в плавающем формате FP16 (включая любые операции блендинга и даже MSAA). Сжатие FP16 текстур включая 3Dc.
- Новый RGBA (10:10:10:2) целочисленный тип данных в буфере кадра для более качественного рендеринга без привлечения FP16.
- Новый качественный алгоритм анизотропной фильтрации (пользователю доступен выбор между более быстрой и более качественной реализацией анизотропии), улучшена трилинейная фильтрация
- Поддержка "двустороннего" буфера шаблонов
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- Контроллер памяти с 512-битной внутренней кольцевой шиной (4 канала памяти, программируемый арбитраж). Эффективное кэширование и новая более эффективная реализация HyperZ
- 2xRAMDAC 400 МГц
- 2xDVI интерфейса c поддержкой HDCP
- TV-Out и TV-In интерфейс, HDTV-Out
- Аппаратный видеопроцессор (для задач компрессии, декомпрессии и постобработки видео), новое поколение, способное ускорять работу с H.234 — новым алгоритмом компрессии видео, используемом в HD-DVD и Blu-Ray видео дисках.
- 2D ускоритель с поддержкой всех функций GDI+
Далее мы подробно поговорим о новой архитектуре ATI а пока отметим самые важные моменты: всестороннюю поддержку SM3 включая эффективную реализацию переходов, работу с форматами хранения и рендеринга FP16 без каких либо ограничений (как и с целочисленными, включая MSAA и сжатие текстур), FP32 точность вычислений внутри чипа.
Начальная линейка карт
RADEON |
Чип (конвейеров) |
частота ядра / памяти, МГц |
Объем памяти, Мбайт (бит) |
Цена, $ |
X1800 XT |
R520 (16) |
625 / 750 |
512/256 (256) GDDR3 |
549/499 |
X1800 XL |
R520 (16) |
500 / 500 |
256 (256) GDDR3 |
449 |
X1600 XT |
RV530 (12, 4TMU) |
590 / 690 |
256/128 |
249/199 |
X1600 PRO |
RV530 (12, 4TMU) |
500 / 390 |
256/128 |
199/149 |
X1300 PRO |
RV515 (4) |
600 / 400 |
256 (128) GDDR3 |
149 |
X1300 |
RV515 (4) |
450 / 250 |
256/128 (64) DDR |
129/99 |
X1300 HM |
RV515 (4) |
450 / 500 |
32 ( 32, HM) GDDR3 |
79 |
Позже, несомненно появятся новые референсные конфигурации и новые карты от ATI, а пока отметим некую задержку, практически до декабря, с доступностью продуктов на базе RV530 (чип разрабатывался несколько позже R520 и несет в себе некоторые черты будущего R580, отсюда видимо и сдвиг с массовым производством), и задержку с доступностью самого старшего продукта линейки — X1800 XT — явление скажем так досадное, и намекающее на то, что на данный момент целый месяц этот самый быстрый ускоритель будет скорее пресс-картой (ведь обозреватели свои карты получили к анонсу) и призван конкурировать с G70 в обзорах а не на полках магазинов. Возможно, опять таки, виною выход годных чипов, или иные соображения, но ранее 5 ноября мы в магазинах эту карту не увидим.
Учитывая высокий конкурентный потенциал RV530 и шансы 1800XT более-менее заметно обойти GeForce 7800 GTX, можно только посетовать на эти задержки — было бы куда как лучше, если бы все продукты новой линейки, давно ожидаемой поклонниками ATI, появились в продаже уже сейчас.
Архитектура R520
В этот раз мы не будем приводить собственную схему, а приведем схему из материалов ATI — т.к. она в этот раз отличается похвальной детализацией и отображает все необходимые нам моменты. Давайте посмотрим внимательно:
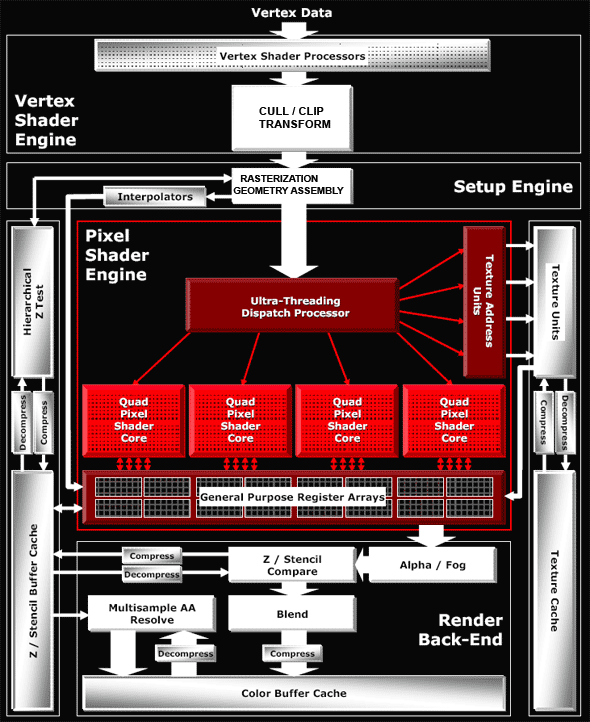
Архитектура вершинных процессоров
В наличии 8 одинаковых вершинных процессоров (на схеме они скрыты в блоке Vertex Shader Processors), соответствующие SM3 требованиям и построенных по стандартной для ATI схеме 3+1 (ALU каждого вершинного процессора может исполнять две разные операции одновременно, над тремя компонентами вектора и четвертой компонентой или скаляром). Фактически, вершинные процессоры стали очень похожими на то, что мы видели в NV4X и G70, за единственным исключением — там была схема 4+1 (за такт обрабатывался четырех компонентный вектор и скаляр) а тут 3+1. Потенциально схема примененная в G70 чуть более производительна но реальная разница может быть практически не заметна, тем более в наше время, когда вершинные процессоры редко бывают узким местом во время рендеринга. Позже мы внимательно исследуем (в том числе практически) вопрос реализации и эффективности доступа к текстурам из вершинных процессоров ATI.
Архитектура пиксельной части
А вот тут и кроется все самое интересное. Посмотрите на схему выше — в отличии от NVIDIA, текстурные модули вынесены за общий конвейер и архитектуру чипа можно назвать распределенной — нет общего длинного конвейера по которому крутятся колесом квады, как в случае NVIDIA а совершенно отдельно существует текстурная часть — блоки генерации текстурных координат и доступа к текстурам и сами TMU а отдельно — пиксельные процессоры выполняющие арифметические и другие операции и наборы регистров сданными. Такая схема имеет свои плюсы и минусы. Основной минус — она хорошо годится для механизма фаз, когда сперва идет интенсивная выборка текстур а потом вычисления над ними (шейдеры 1.X и старые программы со стадиями) но чревата неоправданными задержками при зависимых выборках текстур которые достаточно часто встречаются в современных шейдерах 2.X и 3.0. Представьте себе сами — одна команда доступа к текстуре реально вызывает длительную операцию, занимающую много тактов и все это время вычислительный шейдерный процессор должен ждать? Не тут то было — ATI достаточно элегантно решает этот вопрос! Причем решение универсально, оно не только эффективно исполнят зависимые выборки но и повышает по сравнению с подходом NVIDIA КПД работы пиксельной части на шейдерах с условиями и переходами. ATI называет эту технологию гипертредингом.
Итак, как это все работает?
Магический ящик под названием Ultra Threading Dispatch Processor дирижирует исполнением — одновременно в обработке находится 512 квадов, каждый из которых может быть на разных стадиях исполнения шейдера. Вместе с каждым квадом хранится его текущее состояние, текущая команда шейдера, значения ранее проверенных условий (информация о текущей ветке условного перехода). В чипах NVIDIA квады идут по кругу, один за другим, и максимум что возможно — пропуск квадов, не подподающих под текущую ветку условия. В R520 работа организована по иному — наш магический ящик постоянно проверяет наличие свободных ресурсов (будь то текстурные блоки или пиксельные) и направляет стоящие на очереди квады в освободившиеся устройства. Если квад не прошел проверку на условие и не должен обрабатываться той или иной частью шейдера то он не будет болтаться по кругу занимая место и время, вместе с другими квадами которые нуждаются в обработке, а просто пропустит те команды которые ему не нужны и не будет занимать работой текстурный или пиксельный блок. Если квад ждет данных из текстурного блока — он пропустит вперед другие квады, которые пока загрузят пиксельные вычислительные блоки. Таким образом единым подходом убивается сразу два зайца — скрывается латентность доступа к текстурами и эффективно используются вычислительные и текстурные ресурсы во время исполнения шейдеров с условиями и переходами. Эффективность обоих момоентов напрямую зависит от числа квадов которые может удержать в обработке наш магический ящик, и 512 выглядит вполне солидным набором (за такт мы можем получить текстуры для 4 квадов и обработать в пиксельных процессорах 4 квада, таким образом, до 8 квадов находятся в обработке каждый такт, а остальные ждут своей очереди или данных из текстурных блоков).
Несомненно, этот блок достаточно сложный и логика согласования и дирижирования этим набором квадов составляет значительную часть чипа, возможно сравнимую с текстурными и пиксельными процессорами. Тем более, что наборы регистров с данными фактически относятся и к этому блоку — их должно быть очень много, чтобы эффективно хранить все промежуточные вычисления для 512 квадов, ожидающих своей очереди.
Теперь подробнее о пиксельных процессорах и ALU.
Как мы уже видели, пиксельные процессоры сгруппированы по 4 — т.е. фактически мы имеем не 16 отдельных процессоров а 4 процессора квадов, обрабатывающих за один такт 4 пикселя. Каждый такой процессор квадов состоит из следующего набора блоков:
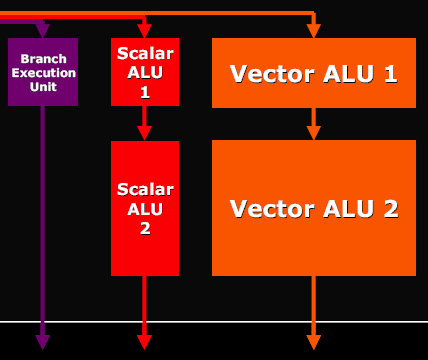
и может выполнить за такт над четырьмя пикселями следующий набор операций:
- VEC3 ADD+модификация и перестановка компонентов (Vector ALU 1)
- Scalar ADD+модификация компонентов (Scalar ALU 1)
- VEC3 ADD/MUL/MAD и другие операции (Vector ALU 2)
- Scalar ADD/MUL/MAD и другие операции (Scalar ALU 2)
- Операцию условного или безусловного перехода (Branch)
Кроме того, не забываем, что кроме этих пяти операций, параллельно может происходить операция адресации текстуры, т.е. запроса данных из TMU, таким образом, в случае оптимального кода шейдера мы получаем пиковую производительность в 6 операций за такт что (в принцыпе) сравнимо с G70, если учесть разницу в архитектурных подходах к исполнению ветвлений. Но, схема примененная ATI, как мы уже отмечали более эффективно справляется с переходами. В практических тестах мы проверим это предположение.
Интересно, что ATI верна своему подходу — 3+1 (могут быть исполнены две разные операции, одна над тремя компонентами вектора, вторая над скаляром, который является четвертой). В большинстве случаев подход NVIDIA (2+2 или 3+1 по выбору) можно считать более эффективным, однако на типичных графических задачах эта разница будет сказываться очень слабо.
Еще один важный момент новой архитектуры — кэширование сжатых данных — как данные глубины и буфера кадра, так и текстурные данные хранятся в КЭШах чипа в сжатом виде и распаковываются и запаковываются налету, по мере доступа к ним из соответствующих блоков. Таким образом эффективность кэширования возрастает, можно считать что объем КЭШей виртуально увеличился в несколько раз.
Логично предположить, что такая архитектура, с разделенными текстурными и пиксельными блоками, может очень хорошо масштабироваться:
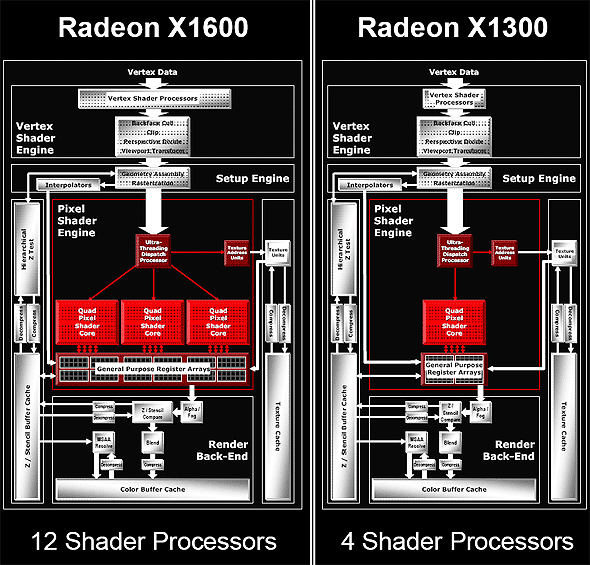
Как мы видим, RV530 и RV515 построены по той же самой схеме.
В RV515 остался только один квад — это упрощает многие аспекты, в том числе и для магического ящика дирижера. В RV530 ситуация сложнее — там три пиксельных процессора квада но только один текстурный блок. Т.е. мы имеем 12 пиксельных процессоров и 4 TMU, пусть и используемых оптимальным путем, практически без простоев. Разумеется, в случае простых шейдеров без сложных вычислений, пиксельные процессоры будут простаивать ожидая текстурные данные, но современные шейдеры, на которые и нацелен этот чип, зачастую производят заметный объем вычислений (5-8 команд) на один доступ к текстуре и тогда такая схема будет оправданной. Судя по всему число транзисторов потраченное на текстурную часть чипа больше чем в случае пиксельных ALU и потому такой дисбаланс оказался оправданным с точки зрения разработчиков из ATI.
Фактически, отказ от 6-8 текстурных блоков и позволил сделать 12 (а не 8 или 4) пиксельных процессора при сохранении той же сложности чипа. Насколько это оправдано на практике — зависит от эффективности текстурных блоков ATI (на которую разработчики компании видимо очень полагаются), от эффективности работы диспатчера-дирижера и от соотношения различных команд в исполняемых шейдерах. Гадать сложно, и мы проверим этот аспект в практической секции, с помошю различных тестов. Пока же заинтригуем читателей постановкой вопроса — был ли такой ход ATI оправданным и как это скажется на конкуренции с NVIDIA особенно в свете скорого появления 12 конвейерного варианта G70 (G71).
Об интерфейсах вывода.
Новые ускорители поддерживают HDCP формат на оба DVI интерфейса, а старшине модели на базе R520 способны выводить на DVI разъемы и HDMI (High Definition Media Interface, интерфейс для вывода изображения и звука на цифровые кинотеатры и другие аудио-видео воспроизводящие устройства нового поколения, подробнее о распространенных интерфейсах можно прочитать в нашем предварительном материале о R520.
Выводы.
- Интересная новая архитектура, с большими возможностями масштабирования и высокой эффективностью использования пиксельных и текстурных ресурсов чипа.
- Наконец-то есть поддержка шейдеров 3.0 и более того, полноценная работа с FP16 текстурами и буфером кадра в любых режимах включая MSAA и сжатие текстур.
- Судя по всему реализация переходов и исполнение шейдеров 3.0 будет происходить заметно эффективнее чем в последних чипах NVIDIA, а на обычных шейдерах 2.0 и ранее, производительность будет как минимум сравнимая, с перевесом в сторону ATI в расчете на один конвейер (в практической части мы проверим это предположение).
- К сожалению, выход линейки был несколько задержан, что может сказаться на конкуренции. Более того, будет задержан и выход некоторых карт после анонса на месяц или два.
- Спорным видится и решение сделать 4 текстурных блока у 12 конвейерного RV530 — но только практические тесты помогут нам определиться с его оправданностью.
| 5 октября 2005 г. |
|
|