NVIDIA GeForce 6800 Ultra (NV40)
„асть 1 — особенности архитектуры и синтетические тесты в D3D RightMark
» вот нова€ архитектура перед нами:
работа над ошибками прошлого и
одновременно уверенный задел
на будущее. ¬ какой степени?
—егодн€ мы исследуем оба аспекта.

—ќƒ≈–∆јЌ»≈
- ќфициальные спецификации
- јрхитектура
- 2D и видеопроцессор
- ќсобенности видеокарты
- —интетические тесты в D3D RightMark
- ачество трилинейной фильтрации и анизотропии
- ¬ыводы
—интетические тесты D3D RightMark
»спользованна€ нами верси€ пакета синтетических тестов D3D RightMark Beta 4 (1050) и ее описание доступна на сайте 3d.rightmark.orgонфигурации тестовых стендов:
- омпьютер на базе Pentium 4 3200 MHz:
- процессор Intel Pentium 4 3200 ћ√ц;
- системна€ плата ASUS P4C800 Delux (i875P);
- оперативна€ пам€ть 1024 MB DDR SDRAM;
- жесткий диск Seagate Barracuda IV 40GB;
- операционна€ система Windows XP SP1; DirectX 9.0b;
- мониторы
ViewSonic P810 (21") иMitsubishi Diamond Pro 2070SB (21"); - драйверы NVIDIA верии 60.72;
- драйверы ATI версии 6.436 (CATALYST 4.4).
ƒл€ начала исследуем соответствие за€вленных характеристик (16 пикселей за такт, 16 TMU и т.д.) действительности. »так :
“ест Pixel Filling
ѕикова€ производительность выборки текстур (texelrate), режим FFP, дл€ разного числа текстур накладываемых на один пиксель:
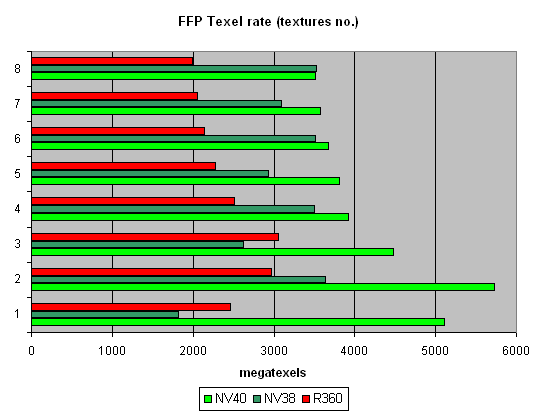
“еоретический максимум NV40 в этом тесте 6.4 гигатекселов в секунду. ¬ действительности мы почти достигли 6 гигатекселов, что однозначно свидетельствует о наличии 16 текстурных модулей. ¬ случае одной текстуры результат чуть меньше чем в случае двух — видимо мы страдаем от недостаточной полосы пропускани€ буфера кадра, а далее на лицо плавна€ зависимость — с каждой новой текстурой скорость закраски постепенно падает. —качков между четными и нечетными числами (как у NV38) свойственных конфигураци€м с двум€ TMU на пиксель нет, и наоборот, картина очень похожа на R360. “аким образом, можно сделать вывод о соответствии схемы 16х1 действительности. »нтересно, что максимум достигаетс€ R360 на трех текстурах, а NV40 на двух — это говорит о более оптимальной работе последней с буфером кадра при закраске. »нтересно, что по мере роста числа текстур NV38 догон€ет старший чип — в случае четного числа текстур эффективность выборки NV38 близка к теоретическому пределу. ќднако, мы помним, что в реальных задачах все не так просто — более слабый на выборке текстур R360 порою выигрывал у NV38 числом конвейеров и вычислительной мощью. ƒалее мы посмотрим как с этим обсто€т дела у NV40.
ј сейчас — скорость закраски буфера кадра (fillrate, pixelrate), режим FFP, дл€ разного числа текстур накладываемых на один пиксель:
»так, NV40 новый король горы. ѕикова€ скорость работы с буфером кадра (0 текстур Цзакраска цветом и одна текстура) вдвое выше, чем у R360 и в два с половиной раза выше, чем у NV38. ¬прочем, на четном числе текстур (2 и более) этот чип реабилитирует себ€. », хот€ теоретический предел 6.4 гигапиксел€ в секунду не достигнут, налицо возможность записывать 16 пикселей за такт. »так, обрабатываетс€ целых 4 квада (2х2) за один такт, т.е. 16 пикселей. »нтересно, что с увеличением числа текстур скорость закраски падает быстрее, чем у предыдущего поколени€ — сказываетс€ небольша€ частота €дра и увеличение числа текстурных блоков вдвое, по сравнению с пиксел€ми, число которых возросло вчетверо.
ѕосмотрим, как скорость закраски зависит от версии шейдеров:
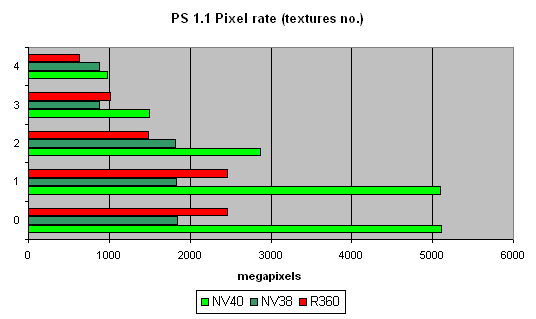
та же картина что и в случае FFP,
ѕосмотрите на курьез судьбы, на родном детище ATI, шейдерах 1.4 ныне NVIDIA €вл€етс€ четким лидером. “акова сел€ви.
ќтлично, если NV38 в силу своих архитектурных тонкостей досадно замедл€лс€ в этом тесте на пиксельных шейдерах 2.0 (дополнительные такты уходили на некоторые команды шейдеров 2.0 реализованные в NV38 как макросы) что делало более выгодным использование на NV38 шейдеров 1.4, чем 2.0 (вот парадокс — на R360 все наоборот, 2.0 производительнее 1.4). “еперь справедливость восстановлена, а просчеты исправлены — NV40 показывает себ€ ровно во всех верси€х шейдеров. ќтметим, что старичок R360 не так уж и плохо смотритс€ на фоне NV40.
—водный график NV38 и NV40 дл€ некоторого числа текстур, как доказательство успешной работы над ошибками:
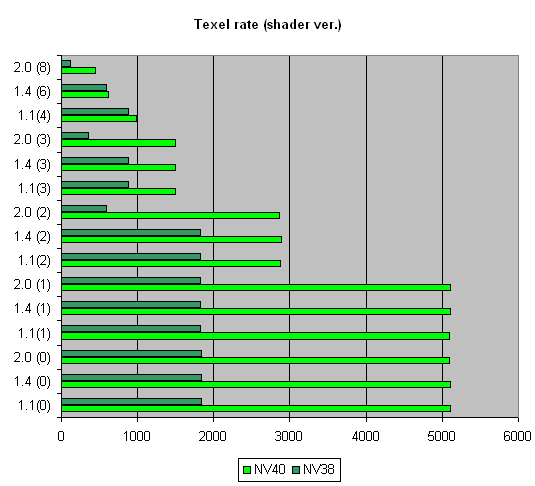
»так, вырисовываетс€ следующа€ картина предпочтений:
¬ерси€ |
1.1 |
1.4 |
2.0 |
NV40 |
ќптимально |
ќптимально |
ќптимально |
NV38 |
ќптимально |
ќптимально |
Ќе оптимально |
R360 |
ќптимально |
Ќе оптимально |
ќптимально |
ј теперь посмотрим, как текстурные модули справл€ютс€ с кэшированием и билинейной фильтрацией реальных текстур различных размеров:
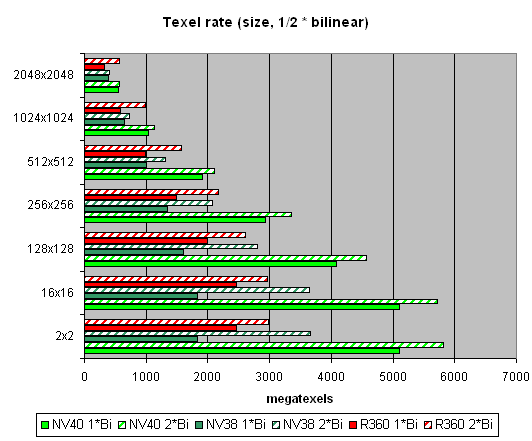
ѕриведены данные дл€ разных размеров текстур, одна и две текстуры на пиксель. Ќа размерах вплоть до 512х512 преимущество 16 текстурных модулей NV40 налицо. –езультаты близки к теоретическому пределу. ј далее, по мере роста размера текстур, все упираетс€ в пропускную полосу пам€ти. Ёффективность кэшировани€ достойна похвал — на самом ходовом размере 128х128 мы достигаем более чем четырех гигатекселей. ѕосмотрим, как изменитс€ картина в случае трилинейной фильтрации:
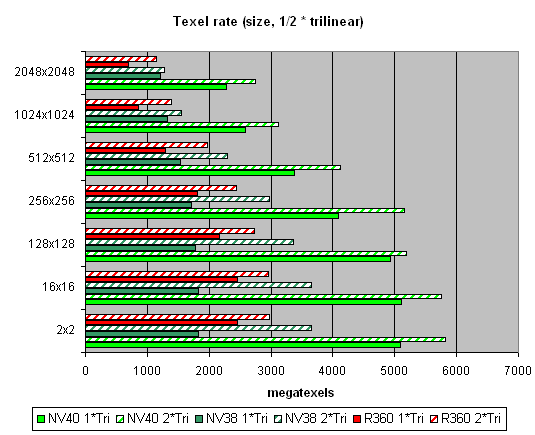
¬от это да! «десь преимущество NV40 еще более заметно. ¬се правильно — больше текстурных блоков — больше результатов трилинейной фильтрации, кроме того, наличие мип уровней позвол€ет эффективно кэшировать данные текстур. ј двукратное преимущество однозначно показывает, что в этом аспекте NV40 пока нет равных.
Ќапоследок предельный случай восьми трилинейно фильтруемых текстур:
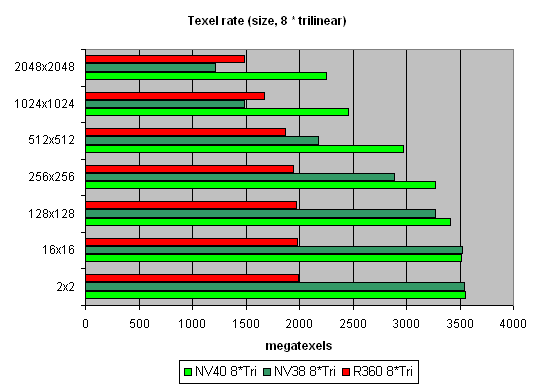
Ћишний раз показывает нам, что реализаци€ выборки текстур — сильна€ сторона NVIDIA.
ј теперь посмотрим на зависимость производительности текстурных модулей от формата текстур:
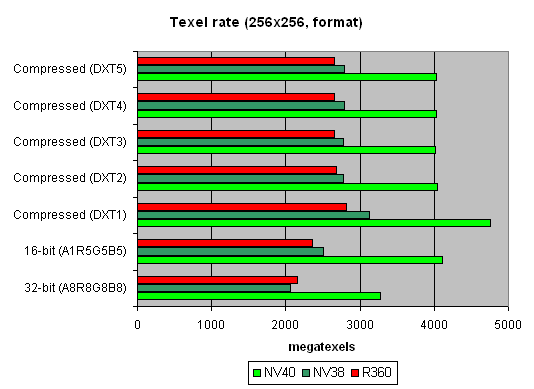
Ѕольше размер:
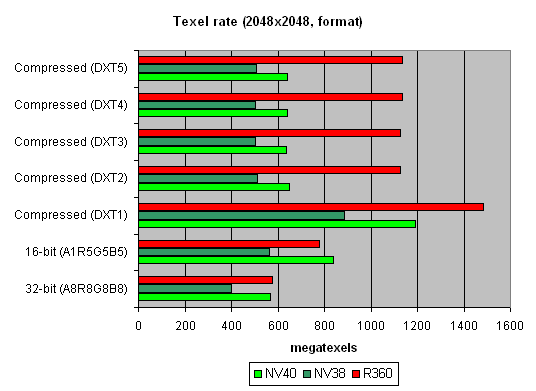
»нтересна€ картина. ѕочему R360 так выигрывает, даже у NV40 в случае больших размеров сжатых текстур? ќтвет прост — в текстурном кэше NVIDIA хран€тс€ уже распакованные текстуры, приведенные к формату 32 бита. ¬ текстурном кэше ATI — все еще сжатые. — одной стороны эффективность выборки текстур NVIDIA будет выше — меньше простоев во врем€ распаковки, меньше задержка, с другой стороны при большом размере текстур фактор занимаемого ими места может вывести ATI в лидеры — NV40 упретс€ в пропускную полосу пам€ти и даже 16 TMU его не спасут. „то собственно и происходит на втором графике. ¬ реальных приложени€х баланс может склонитьс€ как в ту, так и в иную сторону, в зависимости от шейдеров, числа и размера текстур и прочих параметров сцены.
»так, в общем и целом, можно констатировать два факта:
- NV40 чемпион по закраске и выборке текстур, 16 пикселей за такт, 16 TMU, да и легендарна€ эффективность работы TMU и буфера кадра от NVIDIA по прежнему в силе.
- ƒосадные неравномерности поведени€ предыдущего поколени€ NVIDIA на пиксельных шейдерах 2.0 устранены.
“ест Geometry Processing Speed
—амый простой шейдер — предельна€ пропускна€ способность по треугольникам:
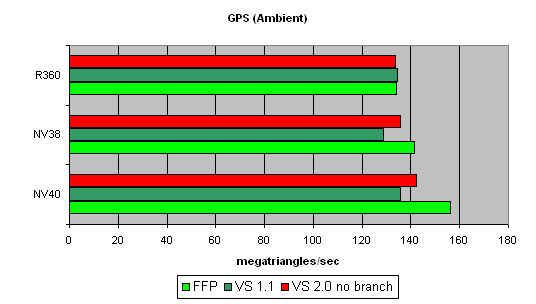
ѕочему результаты NV40 почти не превышают предыдущего поколени€? ¬опрос сложный. —уд€ по всему вершинные процессоры чипа просто не разворачиваютс€ в полную силу на столь примитивной задаче. ѕроверим наше предположение далее, на более сложных задачах. ј пока отметим, что характер зависимости скорости NV40 от версии шейдера очень точно повтор€ет NV38 — как мы уже предполагали, может оказатьс€, что в вершинных процессорах этих чипов много общего.
Ѕолее сложный шейдер — один простой точечный источник света:
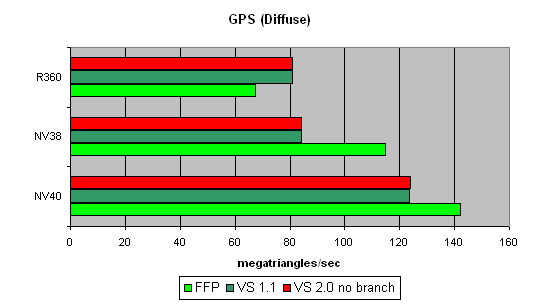
¬от здесь преимущество NV40 уже начинает про€вл€тьс€. ¬се верно, слишком короткий шейдер просто упиралс€ в скорость работы буферов и механизма выборки вершин, а здесь у вершинного процессора NV40 по€вилась возможность поработать в плане вычислений и результат не замедлил сказатьс€. »нтересно, что по-прежнему FFP €вл€етс€ лучшим вариантом дл€ NVIDIA и худшим дл€ ATI — сказываютс€ дополнительные аппаратные блоки дл€ ускорени€ расчета освещени€ в рамках стандартных требований FFP.
”сложн€ем задачу далее:
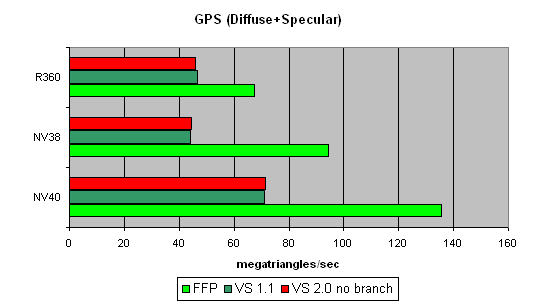
«десь FFP лидер даже в случае ATI — алгоритм FFP несколько проще того, что был использован в вершинном шейдере. «десь NV40 €вный лидер.
ј теперь сама€ сложна€ задача, три источника света, причем, дл€ сравнени€ в вариантах без переходов, со статическим и динамическим управлением исполнением:
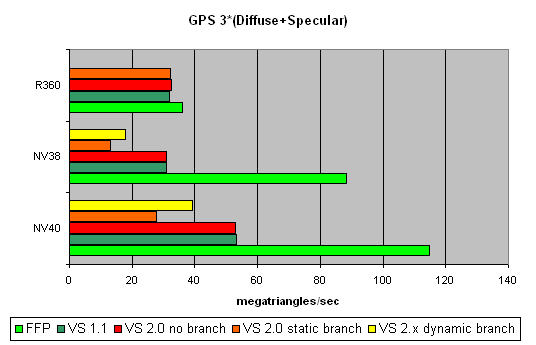
—татические переходы заметно удар€ют по чипам NVIDIA . ѕричем, характер падени€ одинаковый как в NV38, так и в NV40 — можно предположить, что их вершинные процессоры устроены в этом плане одинаково. ѕарадокс в том, что динамические переходы на чипах от NVIDIA выгоднее статических. ¬ случае ATI все достаточно ровно.
»так :
- FFP значительно быстрее на чипах NVIDIA, зачастую вдвое.
- ’арактер зависимости от типа шейдера одинаковые дл€ NV38 и NV40 — видимо архитектура вершинных процессоров очень близка.
- —татические переходы на ускорител€х NVIDIA исполн€ютс€ не оптимально.
“ест Pixel Shaders
ѕерва€ группа шейдеров — достаточно простых дл€ исполнени€ в реальном времени, 1.1, 1.4 и 2.0:
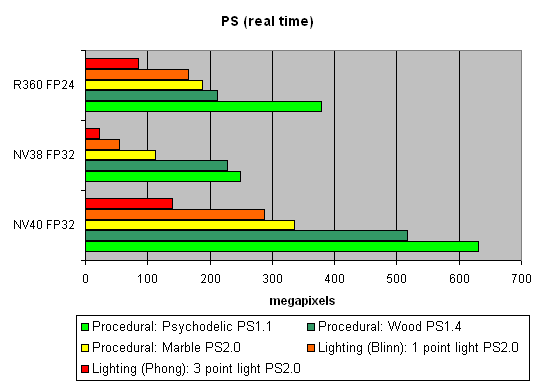
„то еще сказать — свершилось. „еткое преимущество NV40 и соответственно работа над ошибками NV38 налицо. Ќова€ топологи€ пиксельного процессора, новые ALU и текстурный модуль прекрасно справл€ютс€ с различными верси€ми шейдеров.
ѕосмотрим, каков прирост при использовании 16 битной точности плавающих чисел:
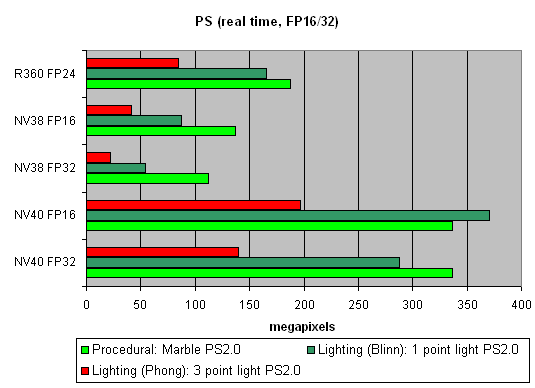
ѕреимущество 16 битной точности дл€ NV40 есть, в некоторых шейдерах больше, в некоторых меньше. », что самое интересное, порой более заметное чем в случае NV38. ¬прочем, здесь может играть роль компил€тор — со временем, по мере его оптимизации, будет уменьшаетьс€ число задействованных временных переменных и проходов карусели пиксельного процессора и, как следствие, разница может уменьшитьс€ — FP32 подт€нетс€ к результатам FP16.
ј теперь посмотрим на действительно сложные, « кинематографичные» шейдеры:
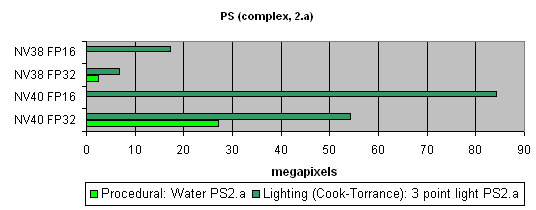
«десь NV40 демонстрирует просто феноменальную производительность в несколько раз превышающую результаты предыдущего поколени€. ≈сть где развернутьс€ — дес€тки зависимых выборок текстур, множество временных переменных, сложный код. ¬от почем разница 16 и 32 бит столь заметна.
Ќа последок, исследуем зависимость скорости от использовани€ арифметических или табличных методов вычислени€ sin, pow и нормализации векторов, отдельно дл€ всех чипов:
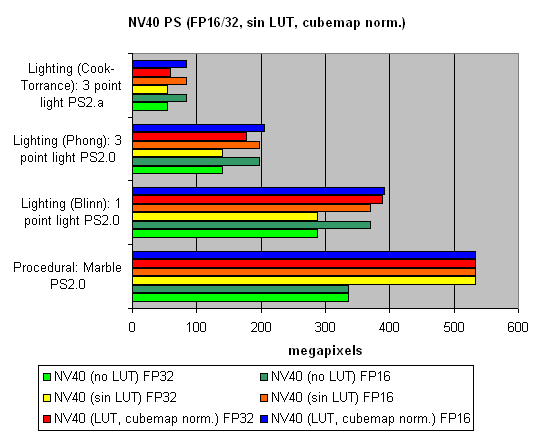
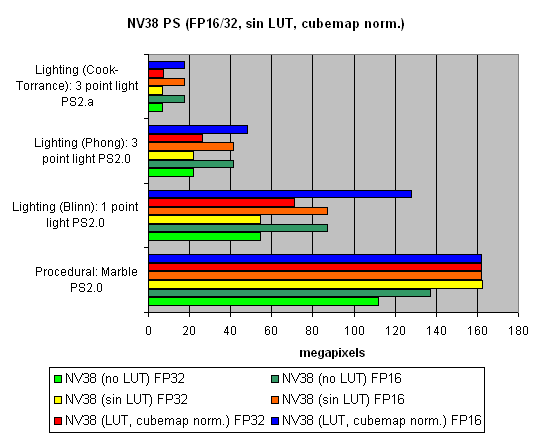
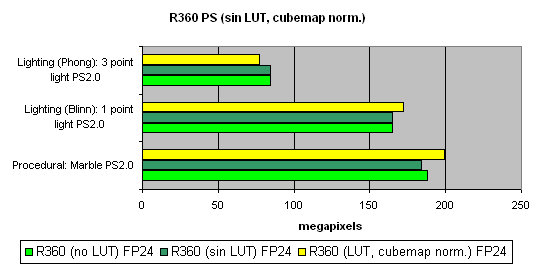
ќбща€ мораль такова :
- Ћучше 16 бит, чем 32
- Ћучше таблицы, чем арифметические вычислени€ дл€ NVIDIA (эффективна€ выборка текстур)
- Ћучше вычислени€, чем таблицы дл€ ATI (выборка текстур менее эффективна)
»того, по пиксельным шейдерам :
- ѕроизводительность вне конкуренции, с печальным прошлым предыдущего поколени€ покончено.
- Ќаличие возможности динамического управлени€ вычислени€ми не сказалось на производительности обычных шейдеров в худшую сторону.
- »справлены слабые места, св€занные с временными переменными, но все еще можно ждать прироста от компил€тора в новых верси€х драйверов — он пока не столь эффективен, как у NV38
“ест HSR
ƒл€ начала пикова€ эффективность (без текстур и с текстурами) в зависимости от сложности геометрии: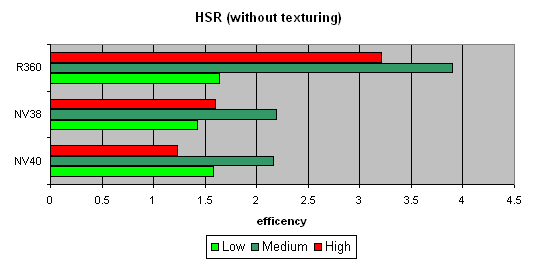
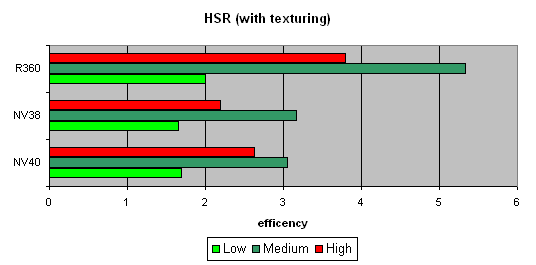
«аметно, что ATI лучше переносит средние и сложные сцены — сказываетс€ наличие двух уровней уменьшенных Z буферов (кроме базового). ” NVIDIA традиционно один дополнительный уровень, поэтому эффективность HSR в случае оптимального баланса сцены (средн€€ сложность) несколько ниже. роме того, более эффективна€ закраска и текстурирование также снижает пиковую эффективность HSR (точнее уменьшаетс€ штраф за не отброшенные зоны).
’арактер зависимости показывает, что алгоритм со времен NV38 не изменилс€. «ато абсолютные цифры существенно возросли:
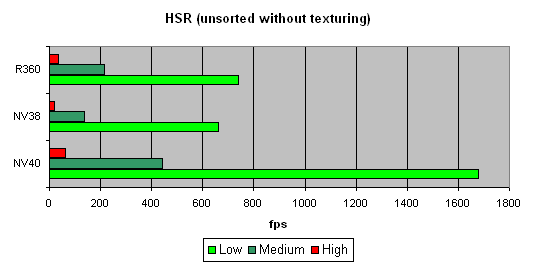
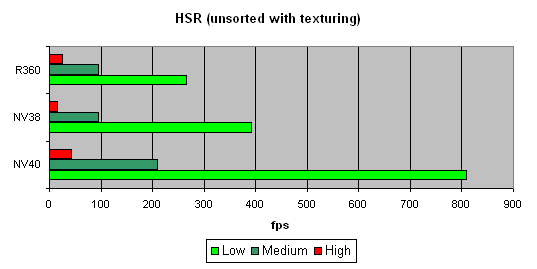
¬идно, что NV40 вне конкуренции, как минимум вдвое опережа€ других участников.
¬ывод :
- јлгоритм HSR не претерпел серьезных изменений
- Ќо его обща€ производительность увеличилась, что нормально, учитыва€ большее число отправл€емых на отрисовку (или отбрасываемых) за такт квадов.
“ест Point Sprites.
я думаю, читател€м не составит труда самим сделать выводы. —прайты давно перестали быть попул€рным новшеством и зачастую проигрывают треугольникам по скорости вывода.
[ ѕредыдуща€ часть (2) ]
[ —ледующа€ часть (4) ]
| 21 апрел€ 2004 г. |

|
| ƒополнительно |
|





