

Помимо фотографий графического ускорителя NVIDIA Tesla, во время официального анонса графического процессора GT300 была показана новая информация касательно архитектуры с кодовым названием Fermi. На слайдах продемонстрированы общие характеристики новинки, организация потоковых мультипроцессоров и их структура, результаты производительности в вычислениях чисел с плавающей запятой и другое.
Как и сообщалось ранее, графический процессор нового поколения GT300 содержит три миллиарда транзисторов, имеет 512 шейдерных ядер и обеспечивает производительность в вычислениях с двойной точностью, в восемь раз превышающую производительность чипа GT200.

Потоковые мультипроцессоры расположены вокруг общей кэш-памяти второго уровня. На слайде каждый такой мультипроцессор представляет собой вертикальный прямоугольник, который содержит оранжевую часть (планировщик и организатор), зелёную часть (исполнительные модули) и голубые части (файлы регистров и кэш-память первого уровня).
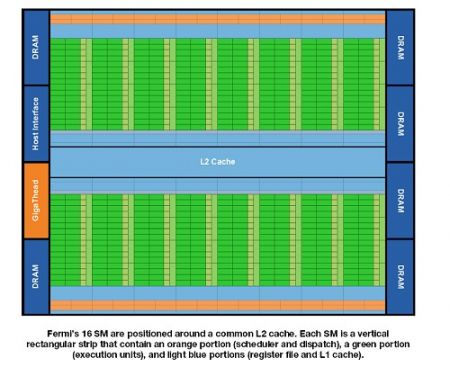
На следующем слайде показана внутренняя структура мультипроцессора. Каждый из 16 мультипроцессоров имеет 32 шейдерных ядра, что в сумме даёт 512 так называемых CUDA-ядер.

Что касается памяти, новый GPU оснащён шестью 64-разрядными контроллерами памяти GDDR5, что даёт 384-битную шину памяти и поддержку до 6 ГБ памяти GDDR5. Fermi является первой архитектурой, поддерживающей код коррекции ошибок (ECC) для данных, хранящихся в памяти. Технология NVIDIA Parallel DataCache значительно ускоряет математические вычисления и выполнение других функций.
На слайде показано сравнение производительности в вычислениях чисел с плавающей запятой двойной точности между видеокартой Tesla C1060 и новой моделью на архитектуре Fermi. В тесте с 20480 объектами новинка показывает результат 18,16 кадров в секунду, производя за секунду 7,61 млрд итераций. Её предшественница способна лишь на 3,52 кадра в секунду, выполняя за секунду 1,47 млрд итераций.

Решения на архитектуре Fermi называют первыми в мире вычислительными GPU. Благодаря набору инструкций Parallel Thread eXecution второго поколения (PTX 2.0), в них реализована аппаратная поддержка таких средств программирования, как C, C++, Fortran и множество других функций (таких как унифицированное адресное пространство, OpenCL и DirectCompute).
Основной задачей Fermi считают перенос вычислений больших массивов данных на GPU, оставив в ответственности центрального процессора обработку множества различных инструкций.
К сожалению, на конференции GPU Technology Conference не были упомянуты даты выхода продуктов на архитектуре Fermi. Ожидается, что в ближайшие месяцы компания NVIDIA закончит работу над чипом GT300, и на его основе появятся продукты серий GeForce, Quadro и Tesla.
В заключение, приводим сравнительную таблицу характеристик чипа GT300 и его предшественников:
| GPU | G80 | GT200 | GT300 |
| Транзисторов | 681 млн | 1,4 млрд | 3,0 млрд |
| Потоковых процессоров | 128 | 240 | 512 |
| Вычислений* двойной точности | — | 30 FMA/такт | 256 FMA/такт |
| Вычислений* одинарной точности | 128 MAD/такт | 240 MAD/такт | 512 FMA/такт |
| Warp-планировщиков** | 1 | 1 | 2 |
| Спец. функциональных модулей (SFU)** | 2 | 2 | 4 |
| Разделяемой памяти** | 16 КБ | 16 КБ | до 48 КБ |
| Кэш-памяти L1** | — | — | до 48 КБ |
| Кэш-памяти L2** | — | — | 768 КБ |
| Поддержка ECC памяти | — | — | + |
| Конкурентных ядер | — | — | до 16 |
| Ширина адреса | 32 бита | 32 бита | 64 бита |
* вычислений чисел с плавающей запятой ** на потоковый мультипроцессор
Источник: HardwareZone