

Вот уже который месяц сетевая общественность продолжает обсуждать перспективы и последствия слияния (путем поглощения) компаний AMD и ATI. Но, кроме этого, появилась и еще одна модная тема, связанная с суперкомпьютерами и вычислениями. Судя по тому, сколько внимания уделяется этой теме, может возникнуть ощущение, что всем без исключения, вплоть до тех, кто работает дома на персональных компьютерах, хочется располагать вычислительными системами, способными обрабатывать триллионы операций с плавающей точкой в секунду. Но об этом — чуть позже.
AMD + ATI = Fusion
Итак, сделка года или, вполне возможно, даже нескольких последних лет, завершена — компания AMD официально завершила поглощение ATI Technologies. В ходе операции, AMD приобрела акции ATI, заплатив за них денежными средствами (4,3 млрд. долларов). и собственными акциями (еще 58 млн.). Для финансирования сделки понадобились собственные наличные средства AMD и 2,5 млрд. долларов в виде ссуды, полученной от Morgan Stanley Senior Funding.
Планы AMD после объединения предусматривают выпуск в 2007 году интегрированных платформ для нескольких сегментов рынка, включая мобильные, игровые и мультимедийные системы. Подтверждаются ранние слухи о том, что AMD намеревается создать новый класс x86-совместимых решений, в которых центральный процессор (CPU) и графический процессор (GPU) будут интегрированы «на уровне кремния». Проект, включающий большое количество новшеств, получил кодовое название Fusion (англ. — сплав, слияние, синтез). Предполагается, что процессоры платформы AMD Fusion станут следующим шагом в развитии технологии ЭВМ и продемонстрируют более высокие показатели производительности в расчете на ватт потребляемой мощности по сравнению с сегодняшними решениями. Появление первых таких изделий ожидается в конце 2008 или начале 2009 года. Согласно планам AMD, новая концепция будет реализовываться во всех приоритетных направлениях разработки, включая процессоры для ноутбуков, настольных ПК, рабочих станций и серверов, а также — в изделиях потребительской электроники и «решениях, приспособленных к уникальным нуждам быстрорастущих рынков».
Практически одновременно с первыми сообщениями о том, что AMD готовится приобрести ATI, стали появляться новости и о том, что Intel может купить NVIDIA. И хотя, судя по всему, эти слухи довольно далеки от истины (некоторые аналитики предполагают, что даже AMD будет выгодно выделить в отдельное дочернее предприятие бизнес по разработке, производству и продаже графических адаптеров), акции NVIDIA на этой волне заметно прибавили. В общем-то, наверное, Intel и не нужно приобретать NVIDIA — последние аналитические данные показывают, что по продажам интегрированных графических ядер компания по-прежнему занимает первое место, кроме того, увидев намерение AMD интегрировать графическое ядро непосредственно в процессор, Intel тоже планирует провести свои исследования в этом же направлении.
Однако, очевидно, что определенные изменения в стратегии как Intel, так и NVIDIA, перед лицом объединения AMD и ATI произойти всё-таки должны. Это необходимо обоим компаниям для обеспечения поставок наборов микросхем системной логики для процессоров Intel, так как в то, что ATI позволит AMD покупать чипсеты NVIDIA в больших количествах, в NVIDIA не верят. В Intel, в свою очередь, понимают, что поток поставок чипсетов ATI для процессоров Intel скоро прекратится. Сейчас Intel держит примерно 8-10% пакет акций NVIDIA. В случае увеличения принадлежащего Intel пакета акций, вполне возможно, до блокирующего, весьма вероятно снижение разработок и поставок чипсетов NVIDIA для AMD. Но к этому, судя по всему, NVIDIA уже морально готова.
Как бы ни сложились взаимоотношения теперь уже трех заинтересованных сторон, к двум из них появились новые претензии: SGI подала иск против ATI Technologies, обвиняя производителя графических процессоров в нарушении своего патента, а против Intel выступила Transmeta.
В исковом заявлении SGI утверждается, что в графических чипах ATI Radeon используется технология, права SGI на которую закреплены патентом США № 6650327 (заявка подана в 1998 году, удовлетворена — в 2003; касается использования чисел с плавающей запятой для описания графических элементов с целью «уравновесить диапазон и точность сохраняемых значений»). Известно, что SGI требует компенсации нанесенного ущерба, однако, сумма не называется. Интересно, что иск выдвинут всего лишь несколько дней спустя после того, как SGI официально вышла из-под действия так называемого закона о защите от банкротства, получив новое финансирование, сокращенную линию продуктов и новый руководящий состав. По утверждению руководителя SGI, его компания лицензировала упомянутую технологию основным конкурентам ATI (вероятно, в том числе и компании NVIDIA), и намерена «агрессивно защищать» свою интеллектуальную собственность.
Что касается Transmeta, то её претензии заключаются в обвинениях к Intel в нарушении промышленным гигантом аж десяти патентов и их незаконного использования в процессорах, начиная от Pentium Pro и заканчивая последними Core 2 Duo. В частности речь идёт о технологиях энергосбережения, включая Enhanced SpeedStep, которая снижает частоту процессора в моменты малой его загрузки с целью снижения энергопотребления.
Transmeta являлась первой компанией, поставившей во главу угла повышение энергетической эффективности своих продуктов, её процессоры Crusoe могли работать с теми же приложениями, что и чипы Intel, потребляя меньшее количество энергии (правда и работая всё-таки медленнее). После дебюта Crusoe в 2000 году были заключены соглашения на его использование с Sony и Fujitsu, перспективы процессоров виделись весьма неплохими, однако дальше Transmeta начала испытывать трудности с выпуском более быстрых версий, что привело к прекращению выпуска новых продуктов серии. И если претензии компании к Intel окажутся обоснованными, это станет для неё неплохой возможностью поправить свои финансовые дела.
ПК для бедных: Classmate PC и OLPC
В прошлых iТогах мы уже уделили внимание проектам Classmate PC и OLPC. Благодаря энтузиазму сторонников одних и усилиями маркетологов других, общественности стала доступна новая порция технических деталей. Напомним, что когда говорят о Classmate PC, речь идет об устройстве, первоначально носившем кодовое название Eduwise, и представляющем собой миниатюрный и недорогой компьютер, разрабатываемый Intel для систем образования развивающихся стран — в первую очередь, Мексики, Бразилии, Нигерии и Индии.
На IDF была объявлена цена — не более 400 долларов — и срок выхода компьютера на рынок: конец текущего — начало будущего года. Похоже, что поставки Classmate PC уже начались, и на снимках вы видите серийный образец изделия. Они дают представление о размерах компьютера в целом и его экрана, расположении клавиш и других органов управления.
Для сравнения рядом с Classmate PC помещен ноутбук IBM Thinkpad T60. Обратите внимание, насколько Classmate PC меньше. Между тем, Classmate PC может работать под управлением Windows или Linux, имеет 256 МБ оперативной памяти (DDR2) и 1 ГБ постоянной (ее роль играет флэш-память). 
В закрытом виде становится видна ручка для переноски.
Стремясь привлечь побольше внимания к своему проекту, инициаторы OLPC (One Laptop Per Child), позже именуемый 2B1 Children's Machine, решили дать своему детищу еще одно новое название — XO.
Изменения коснулись не только названия, но и аппаратной составляющей готовящихся продуктов. Можно вспомнить, что изначально планировалось, что в такие мобильные ПК будет встроен генератор с ручным приводом, а энергии от одной зарядки должно хватать на очень недолгое время (15-20 минут). После того, как на одной из демонстраций ручка привода сломалась, было принято решение заменить её конструкцией другого рода, которую нужно дергать на себя.
Напомним спецификации XO (он же CM1 и OLPC):
- Процессор: AMD Geode 366 МГц
- Память: 128 МБ DRAM + 512 МБ флэш-памяти
- Дисплей: двойной ЖК, основной цветной разрешением 1200×900 пикселей и второй ч/б
- Жесткий диск: нет
- Порты/разъемы: 3хUSB, аудиоразъемы
- Сеть: Wi-Fi, Ethernet
- Система энергосбережения, электрогенератор для подзарядки батарей
- ОС: Fedora Core 5.0
Непосредственный производитель таких ноутбуков, компания Quanta, заявляет о том, что она готова начать их производство уже в следующем месяце. Одними из первых получателей XO станут дети Ливии, чьё правительство уже оформило предварительный заказ на 1,2 млн. дёшевых портативных ПК.
iТак, если всё пойдет так, как задумали инициаторы, то AMD своими XO перекроет ценовой сегмент 130-200, а Intel — сегмент 400-600 долларов. С увеличением цены увеличивается и разнообразие и в ценовом диапазоне от 500-600 долларов уже присутствуют недорогие модели ноутбуков на Intel Celeron, AMD Sempron, VIA C7, Transmeta Crusoe. Предложенная недавно Intel инициатива CBB (Common Building Block) окажется в этой связи весьма полезной, так как, с одной стороны, позволит снизить затраты на создание новых комплектующих для ноутбуков, а следовательно, и себестоимость; а с другой стороны, позволит унифицировать комплектующие и избежать ряда проблем, возможно, даже тех, что недавно были вызваны «эпидемией» возгораний аккумуляторных батарей. Есть данные, что первые ноутбуки, построенные на взаимозаменяемых компонентах в рамках инициативы CBB начнут поступать в продажу уже в будущем году. На сегодняшний день известно о том, что к инициативе CBB присоединилось более 25 поставщиков комплектующих, среди которых производители ЖК-панелей, жестких дисков и оптических приводов. А там, глядишь, недалеко и до стандартизации компонент, к которой стремится Intel.
Наблюдатели прогнозируют, что стоимость ультрамобильных ПК (UMPC), сейчас превосходящая 1000 долларов, в будущем году снизится до пределов 600-700 долларов и в дальнейшем, через год или два, сможет упасть до 400-500 долларов. По крайней мере, на такой уровень цен ориентировались представители Intel в кулуарных беседах тайваньского форума для разработчиков (IDF). Напомним, что концепция UMPC, являющихся собой чем-то средним между КПК и ноутбуками (планшетными ПК), подразумевает большую доступность этих портативных ЭВМ, чем доступность ноутбуков. UMPC, отчасти, должны будут помочь в развитии программ охвата вычислительной техникой населения развивающихся и попросту отсталых стран (EduWise, OLPC и т. д. и т. п.) и, судя по всему, станут бюджетным антиподом Vistagami — концепции Microsoft ультрамобильного high-end ПК.
В этой связи чрезвычайно любопытным выглядит тот факт, что будущая стоимость UMPC сопоставима с современной стоимостью high-end автомобильных навигационных систем. И, как утверждает источник, это не осталось незамеченным производителями, начавшими сотрудничество с поставщиками GPS-решений. В частности, Quanta Computer и Inventec планируют использовать микросхемы SiRF в своих UMPC и позиционировать их в рынок портативных навигационных систем. Что ж, неожиданное, хотя и вполне очевидное применение UMPC, позволяющее им занять свою рыночную нишу, уже есть. Но можно не сомневаться, что этим дело не ограничится — конвергенция-то продолжается...
Wintel: союз ненадолго
Уже два с лишним десятилетия программное обеспечение Microsoft и процессоры Intel формируют союз, негласно именуемый Wintel. Союз этот крепким, конечно, назвать нельзя — Intel совсем не возражает против работы систем на своих процессорах под иными ОС, например, Linux, а с недавних пор — и Mac OS. Более того, производителю процессоров, в общем-то, все равно, какое программное обеспечение будет использовано в ПК, лишь бы он был построен на процессоре Intel. Однако, status quo может в обозримом будущем измениться — Microsoft, если верить слухам, находится в процессе разработки своих собственных процессоров.
Утверждается, что компанией создана собственная группа компьютерной архитектуры (Computer Architecture Group), состоящая из исследовательских лабораторий в Редмонде и Кремниевой Долине. Как утверждают онлайновые СМИ со ссылкой на Чарльза Такера, инженера Microsoft, которому предстоит возглавить подразделение компании в «Кремниевой долине», предпосылкой для создания подразделения стала потребность в разработке чипа для следующего поколения игровой консоли Xbox. Кроме того, Microsoft преследует цель добиться сдвигов в технологиях распознавания голоса, до сих пор не слишком совершенных, и данная разработка должна помочь в этой сфере.
Чарльз Такер
Microsoft планирует изучать дизайны процессоров и эффект от применения тех или иных идей на примере экспериментальной системы, разработанной для нее учеными Калифорнийского Университета, и позволяющей изменять и испытывать дизайны без производства чипов.Подробностей о том, что именно пытается сделать Microsoft, не сообщается, говорится лишь о том, что компания заинтересована в интеграции как можно большего количества компонентов в один чип. Можно предположить, что это особенно важно для игровых консолей и портативных устройств, наследников Zune, и именно там впервые появятся процессоры Microsoft. Пока же проект лишь на стадии разработки концепции и говорить о конечных результатах с уверенностью рано.Процессоры
До конца года еще целый квартал, но аналитики уже начали подводить предварительные итоги. AMD, второй по величине производитель микропроцессоров, похоже, увеличит свою долю рынка, в то время, как попытки превосходящего его по размерам конкурента, компании Intel, предпринять ответные шаги, не принесут успеха, по крайней мере, до следующего года. Интересно, что при этом цена акций AMD была максимальной в марте. Если принять мартовское значение за точку отсчета, к настоящему моменту она снизилась на 40%. Источник объясняет это опасениями, которые вызвала у инвесторов ценовая война с Intel. Между тем, компания выдержала испытание и теперь набирает силу вследствие смещения отрасли, в частности, крупных производителей ПК, к использованию процессоров AMD, а не Intel.
По данным Mercury Research, доля AMD на рынке процессоров для настольных систем продолжает расти быстрыми темпами. Во втором квартале она превысила 27%, хотя всего лишь год назад была менее 18%. В аналитической компании Citigroup полагают, что AMD сможет добиться еще большего прироста рыночной доли в 2007 году, частично, за счет привлечения на свою сторону крупнейшего в мире производителя ПК, компании Dell. Специалисты Reuters Estimates ожидают, что по результатам третьего квартала AMD покажет 50% увеличение прибыли или 115,3 млн. долл. в абсолютном выражении при доходе около 1,31 млрд. долл.
Что касается Intel, то третий квартал оказался для компании не слишком удачным. Аналитики оценивают снижение прибыли по сравнению с тем же периодом прошлого года в 55%. Конечно, учитывая соотношение между конкурентами, следует помнить, что в абсолютном выражении прибыль Intel составляет 1 млрд. долл., а доход — 8,6 млрд. (на 14% меньше, чем в прошлом году). Коротко говоря, это самые низкие квартальные показатели компании за последнее время. Предполагается, что в течение ближайших кварталов они начнут выправляться, когда проявится эффект от выпуска новых моделей. В результате, как считают эксперты американской фондовой биржи, прибыль Intel в будущем году увеличится более чем на 33%, тогда как соответствующий показатель AMD возрастет на 17%. Впрочем, критически настроенные наблюдатели добавляют, что прибыль Intel в будущем году несомненно вырастет еще и потому, что компания проводит жесткую линию на сокращение персонала и намерена продолжить урезать расходы, в частности, капитальные вложения в научные исследования.
Intel
Упомянутые выше сокращения кадров и затрат на научные исследования коснутся лишь непрофильных для компании направлений. Впрочем, что именно считать профильными, а что — непрофильными, в Intel до конца не определились, однако, уже примерно полтора десятка тысяч рабочих мест сократили. Несмотря ни на что, прежние вложения продолжают приносить свои плоды и каждый год форум Intel для разработчиков (IDF) приносит с собой массу интересных новостей. Из региональных форумов для разработчиков, проводимых Intel, тайваньский, пожалуй, самый продуктивный. В ходе прошедшего в октябре тайваньского форума вице-президент Intel Мули Эден (Mooly Eden) рассказал о семействе процессоров Penryn, 45-нм версиях архитектуры Core. В принципе, позиция, освещенная докладчиком, уже известна, но услышать её от официального представителя компании — не совсем то же, что получить её из неофициальных источников.
Стратегия, которую Intel называет Tick-Tock Model, заключается в том, что проверенная архитектура переводится на новый техпроцесс, после чего по уже проверенным технологическим нормам выпускаются процессоры новой архитектуры, ближайшими из которых станут Nehalem.
Penryn, помимо уменьшения размера кристалла, будет оптимизирован для пониженного энергопотребления, более высоких тактовых частот, больших объёмов кэш-памяти. Всего в настоящий момент в разработке находятся 15 моделей 45-нм процессоров, первые образцы сойдут с конвейера в первом квартале следующего года, а в продажу такие процессоры поступят во второй половине 2007-го.
Также из слов Эдена можно заключить, что процессоры следующей архитектуры Intel будут иметь встроенный контроллер памяти. О том, что это возможно, разговоры ведутся с начала года, однако только сейчас об этом стали говорить и высокопоставленные сотрудники компании.
Кроме того, большое внимание Эденом было уделено технологии Robson, которая должна впервые появиться в мобильной платформе Santa Rosa. Intel очень верит в скорый её успех и прогнозирует, что уже через два-три года ноутбуки с интегрированной флэш-памятью, ускоряющей загрузку и работу системы, будут очень широко представлены на рынке.
В октябре же Intel представила новый четырехъядерный процессор Xeon MP с кодовым именем Tigerton. Его анонс и начало поставок намечены на вторую половину 2007 года, как сообщили представители компании.
Tigerton — второй четырехъядерный серверный чип компании после Clovertown. Он относится к серии Xeon MP 7000 и будет устанавливаться в многопроцессорные машины.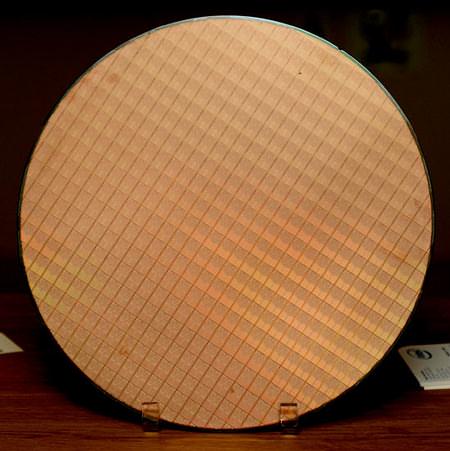
300-мм подложка для двухъядерных чипов, «упакованных» в четырехъядерный Intel Tigerton
Tigerton во всей красе
Прототип четырехпроцессорного сервера Intel. Tigerton установлены под четырьмя массивными алюминиевыми радиаторами
Вентилятор охлаждения северного моста чипсета "Clarksboro" — серверной платформы "Caneland", применяемой для Tigerton
Clarksboro, кстати, будет использовать уже полностью буферируемую память. Это, по задумке разработчиков, должно устранить эффект «бутылочного горлышка» подсистемы памяти при работе четырех процессоров Tigerton в одном сервере.
В ходе мероприятия инженеры Intel продемонстрировали некоторые возможности нового чипа в составе 4-процессорного опытного образца сервера, имеющего в общей сложности 16 ядер. Было использовано ПО SunGard (финансовое моделирование). В планах Intel числятся поставки более 1 млн. 4-ядерных процессоров (Kentsfield для High-End рабочих станций и Clovertown для 2-процессорных серверов) уже к середине следующего года, как отметил Стивен Смит (Stephen Smith), директор Intel Digital Enterprise Group.
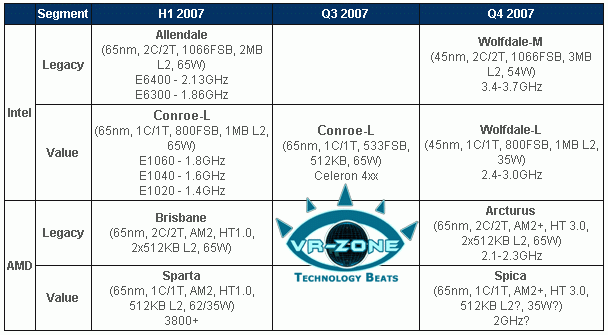
Подытожим также имеющуюся информацию о планах AMD и Intel по производству процессоров для настольных ПК.
![]() Увеличить картинку
Увеличить картинку
Как видим, Wolfdale разделится на две группы: Wolfdale-М и Wolfdale-L (который придет на замену Conroe-L). Первые будут производиться по 45-нм техпроцессу, частота шины составит FSB 1066 МГц, будут обладать 3 МБ кэш-памяти второго уровня (L2), будут выделять ~54 Вт тепла при рабочих частотах 3,4-3,7 ГГц. Wolfdale-L предназначен для бюджетных решений и потому более скромен: тот же 45-нм техпроцесс, но FSB 800 МГц, 1 МБ L2-кэш, процессор выделяет всего 35 Вт тепла при частотах 2,4-3 ГГц.
Что готовят конкуренты решениям Intel? В 4м квартале нас ожидает знакомство с новыми именами — AMD выпустит Arcturus и Spica, о которых мы недавно упоминали. Сразу же хочется отметить отставание AMD в одном технологическом аспекте: Arcturus и Spica — это процессоры, которые будут производиться по 65-нм техпроцессу. Впрочем, их тепловыделение практически сравнимо с Wolfdale-М и Wolfdale-L и составит 65 Вт у Arcturus и 35 Вт (предположительно) у Spica. Как-то компенсировать ситуацию с разностью техпроцессов (в плане технического «вооружения»), наверное, должна будет технология HyperTransport 3.0, с которой будут работать эти оба типа ядра.
Процессоры Arcturus будут иметь по два ядра, у каждого из которых будет 512 КБ кэш-памяти L2, а диапазон рабочих частот составит 2,1-2,3 ГГц. Тип сокета, кстати, сохранится прежним, — АМ2. Что касается одноядерных Spica, то они тоже будут устанавливаться в процессорный разъем АМ2, работать с шиной НТ 3.0, иметь объем кэша 512 КБ (предположительно) и рабочую частоту ~2 ГГц.
AMD
По количеству ядер Intel пока удается быть на полшага впереди AMD — представители компании продолжают рассказывать о деталях своих будущих архитектур, в то время как представители Intel уже их вовсю демонстрируют. В ходе Fall Processor Forum стали известные новые технические детали четырёхъядерных серверных процессоров Opteron (кодовое имя Barcelona), которые станут первыми представителями архитектуры K8L.
Barcelona расширит разрядность блоков, обрабатывающих числа с плавающей запятой, до 128 разрядов, что должно будет ускорить его производительность в активно использующих FPU приложениях, например, кодирования/декодирования медиаданных. В 65-нм Opteron также будет реализовано два независимых контроллера памяти, что позволит обращаться к большему количеству одновременно открытых страниц памяти. Сообщается о поддержке памяти типов DDR2, DDR3 и принципиальной поддержке FB-DIMM, однако с первым поколением FB-DIMM процессоры работать не будут, так как использование этого типа памяти, по мнению AMD, пока себя не оправдывает. Максимальный объём памяти в системах с новыми Opteron сможет составлять до 256 Тбайт.
Прозвучавшее заявление о том, что конфигурация кэш-памяти будет выглядеть, как 64 КБ первого уровня на ядро + 512 КБ второго уровня на ядро + два и более МБ разделяемого кэша третьего уровня ничем новым, по сути, не является.
Для того, чтобы ускорить виртуализацию, в Barcelona AMD применит технологию Nested page tables (вложенные таблицы страниц, для каждой ОС они свои). Данная технология избавляет от дополнительного уровня преобразования адресов памяти в виртуализованных ОС, так что происходит ускорение работы с TLB (translation lookaside buffer, буфер преобразования адреса), и за счет этого «надзирающая» программа-hypervisor может в 4 раза увеличить свою производительность. При этом в Barcelona будут введены новые инструкции, использование которых позволит сократить время переключения в режим гипервизора и обратно на 25%.
Sun
Не устает раздавать обещания и Sun Microsystems, на этот раз касающиеся процессора Niagara 3, третьей реинкарнации своей амбициозной архитектуры. Причем по последним данным, Niagara 3 будет создаваться с учётом требованием 45-нм технологических норм. Напомним, что в настоящее время уже продаются 90-нм процессоры UltraSparc T1 (Niagara), а первые серверы, использующие 65-нм Niagara 2, должны появиться на рынке во второй половине 2007 года. Процессоры первого поколения включают в себя 8 ядер, каждое из которых способно обрабатывать одновременно 4 потока инструкций, Niagara 2 увеличит общее количество обрабатываемых потоков с 32-х до 64-х при том же количестве ядер. Niagara 3 продолжит тенденцию, и в новом поколении также будет улучшена работа контроллера памяти, что повысит пропускную способность подсистемы памяти, будут уменьшены её задержки. Не обошла вниманием Sun и вопросы энергопотребления — обещается что в Niagara 3 показатель производительности на Ватт будет наивысшим.
IBM
Из ровного ряда производителей, наращивающих количество ядер в каждом последующем поколении своих процессоров, несколько выделяется IBM: всякий раз, когда компания публикует новую порцию деталей архитектуры своих процессоров Power6, в воздухе ощущается едва заметный привкус ностальгии по тем временам, когда о быстродействии процессора судили по тактовой частоте. В одной из наших ранних публикаций сообщалось о том, что частота нового поколения процессоров семейства IBM составит до 6 ГГц, чуть позднее — что она будет в пределах от 4 до 5 ГГц.
Но вот уже близится момент официального анонса процессора, а точная тактовая частота по-прежнему не известна. Подытожим имеющиеся в наличие сведения о Power6: частота 4-5 ГГц, 8 МБ кэш-памяти второго уровня (L2) и шина памяти с пропускной способностью 75 ГБ/с. Увеличив тактовую частоту и пропускную способность системы памяти почти вдвое (по сравнению с Power5), IBM, избравшая, в отличие от исповедующего новую парадигму многоядерности Cell, путь наращивания частоты ядра, тем не менее, смогла обойтись без увеличения рассеиваемой теплоты. По мнению источника, этот шаг позволит IBM использовать Power6 в качестве основы для серверной серии P-Series в середине будущего года.
И в то же время, в словах сотрудника группы систем и технологий IBM, сообщившего, что компании «понадобилось масштабировать всю систему, так как простая упаковка большего числа ядер без увеличения кэша и пропускной способности системы памяти не годится»; содержится намек на то, что на Power6 компания может обкатать те технологии, которые впоследствии будут также использованы в Cell. К тому же, в дальнейшем Power6 наверняка пойдет по пути, уже проложенном Power4 и 5. Power4 был первым процессором (в том числе и) для настольных систем, в котором на одном кристалле было размещено два процессорных ядра. Собственно, через месяц Intel начнет предоставлять первые образцы четырехъядерных Kentsfield, в которых два двухъядерных кристалла будут расположены в одном корпусе.
В этой связи весьма любопытно, сможет ли IBM превзойти Intel в «гонке частот»? Последняя остановилась на отметке в 3,8 ГГц для одноядерных Pentium (4), но была вынуждена снизить максимальную частоту для первых своих двухъядерных решений до 2,93 ГГц.
За тем фактом, что IBM удалось удвоить частоту без увеличения тепловыделения стоит серьезная научно-исследовательская работа. Мы уже упоминали о том, что Power6 разработан с учетом требований 65-нм норм, с применением технологий «напряженного кремния», а также «кремния-на-изоляторе» (SOI). Кроме того, IBM использовала переменную длину затвора и переменный уровень порогового напряжения для достижения максимального уровня производительности на ватт потребляемой мощности уже на уровне транзисторов. Будет также небезынтересно сравнить этот показатель с показателями процессоров Intel, лидирующей в «гонке за уменьшение норм» благодаря несколько меньшему числу усложнений техпроцесса. Минимальное напряжение питания — 0,8 В, причем IBM впервые встроила в процессор семейства Power модуль управления питанием, который будет осуществлять мониторинг и управление производительности/потребляемой мощности в зависимости от установленных политик энергопотребления.Платформы
Самым интересным сообщением о платформенных инновациях, пожалуй, было известие о планах Intel интегрировать технологию vPro в Santa Rosa.
Профессиональная редакция мобильной платформы получит имя Centrino Pro и будет поддерживать второе поколение технологии Intel Active Management Technology Ver.2.5 (AMT, помогает администрировать, инвентаризировать, диагностировать и восстанавливать после сбоев компьютеры, даже если они выключены или если на них была нарушена работоспособность операционных систем или жестких дисков. Кроме того, данная технология позволяет изолировать зараженные ПК до того, как вредоносная программа распространится на другие системы корпоративной сети, и уведомляет IT-администраторов об устранении проблемы), технологию виртуализации Intel VT, (она позволяет организовать в одном ПК несколько отдельных независимых аппаратных сред или разделов. Используя эту возможность, IT-администраторы могут изолировать выполнение конкретных задач или операций друг от друга и от различных пользователей ПК, повысив защищенность системы и стабильность ее работы).
Такие ПК будут использовать в дополнение к северному мосту 965GM/PM Express южный ICH8-Enchanced с интегрированным гигабитным сетевым контроллером Intel 82566MM. На продвижение Centrino Pro Intel собирается потратить 300 млн. долларов.
Помимо Centrino Pro, Intel объявила о том, что среди процессоров платформы Santa Rosa не будет таких, чья FSB составляет 667 МГц, а значит, из перечня процессоров будет исключен Core 2 Duo T5500 (1,66 ГГц/2 МБ L2/667 МГц FSB).ГрафикаATI
Самым важным событием для ATI, помимо того, что компания завершила слияние с AMD, стал официальный анонс Radeon X1950 Pro и Х1650 ХТ. Особой изюминкой новинок является то, что одновременно с PCI Express-вариантами будут доступны платы с интерфейсом AGP.

Как и в случае с Radeon X1950 Pro, также поддерживающим Native CrossFire, соединение двух графических адаптеров в CrossFire-режим осуществляется использованием двух локальных разъемов. По сравнению с Radeon X1650 Pro, несколько изменена тактовая частота ядра — до 575 МГц, и памяти — до 1,35 ГГц, число пиксельных процессоров составляет 24 — в целом, как и предполагалось.
А вот планировавшийся к выходу бюджетный графический процессор ATI RV505CE (Radeon X1300CE), готовящийся к выпуску на фабриках TSMC с применением 80-нанометровых технологических норм, увидит свет лишь в ноябре. Специально для него компания разработала дизайн низкопрофильной печатной платы, носящий кодовое имя Blondie. На ускорителях производители смогут расположить до 256 МБ видеопамяти DDR2-400. Помимо того, обещана поддержка технологии HyperMemory, работающей с системной памятью. Таким образом, максимальный объём памяти Radeon X1300CE будет составлять 512 МБ.
Новинка будет поддерживать WDDM, интерфейс Vista Aero, Direct X 9.0c, Shader Model 3.0, Avivo. Что же до характеристик самого графического процессора, то они соответствуют ранней информации: 4 пиксельных и 2 вершинных процессора, 64-битный интерфейс доступа к памяти, тактовая частота — 350 МГц.
Вверху: GeForce 7100GS (NV44), внизу слева Radeon X550SE (RV370), справа: Radeon X1300CER (RV505CE)
ATI рассчитывает на серьезный спрос на такие свои решения со стороны владельцев систем, чья интегрированная графика не будет удовлетворять требованиям Vista. Цена Radeon X1300CE будет более, чем демократичной, — 49 долларов.
В заключение рассказа об ATI — сводная таблица, в которой отражены планы компании по выпуску графических процессоров в 2007 году.
Мы видим, что в следующем году компания будет придерживаться политики, согласно которой новые техпроцессы будут обкатываться на более простых графических чипах, и лишь после этого более совершенные нормы будут внедряться в флагманском решении. Роадмап подтверждает звучавшие ранее заявления о том, что 80-нм нормы являются для производителя малозначимым этапом, более приоритетен быстрый переход на 65-нм технологию — мы видим, что уже в первой половине 2007 года 65-нм техпроцесс будет внедрен в продуктах нижнего и среднего ценовых диапазонов — R630 и R610. Будут ли эти процессоры иметь унифицированную шейдерную архитектуру, пока достоверно неизвестно, однако их принадлежность к семейству R6xx говорит, что это довольно вероятно. Интересно, что R630 задержится на рынке весьма недолго — уже во втором полугодии ему на смену придут сразу два альтернативных решения для среднего ценового сегмента — R660 и R670, одно из которых, очевидно займет место в акселераторах ценою около 150 долларов, а второе — около 200-т.
NVIDIA
NVIDIA в октябре отметилась новым графическим адаптером GeForce Go 7950 GTX, предназначенным для установки в ноутбуки класса замены настольных ПК. 
Новинка является логичным продолжением GeForce Go 7900 GTX, не имея никаких существенных архитектурных новшеств в сравнении с предшественником. Тот же 90-нм техпроцесс, 278 млн. транзисторов, повышены лишь тактовые частоты — до 575 МГц у ядра и до 1,4 ГГц у памяти. Таким образом, новый мобильный флагман NVIDIA должен быть на 10-15% быстрее предыдущей топ-модели, что, впрочем, не будет лишним, учитывая те разрешения, в которых будет использоваться GeForce Go 7950 GTX — 1680×1050 и 1920×1200 пикселей.
Основные характеристики нового видеоадаптера:
- 256 бит интерфейс памяти (4-х канальный контроллер)
- До 512 МБ GDDR-3 памяти
- PCI Express х16 шинный интерфейс
- 24 Пиксельных процессора, по одному текстурному блоку на каждом, с произвольной фильтрацией целочисленных и плавающих FP16 текстур (в том числе анизотропия, степени до 16х включительно) и бесплатной нормализацией FP16 векторов
- 8 Вершинных процессоров, по одному текстурному блоку на каждом, без фильтрации выбираемых значений (дискретная выборка).
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Вычисление и запись до 32 значений глубины и буфера шаблонов за такт (если не производятся операции с цветом)
- Поддержка «двустороннего» буфера шаблонов
- Поддержка специальных оптимизаций прорисовки геометрии для ускорения алгоритмов теней на основе буфера шаблонов и аппаратные карты теней (так называемая технология Ultra Shadow II)
- Все необходимое для поддержки пиксельных и вершинных шейдеров версии 3.0, включая динамические ветвления в пиксельных и вершинных процессорах, выбор значений текстур из вершинных процессоров и т.д.
- Фильтрация текстур в плавающем формате FP16
- В вершинных шейдерах аппаратная фильтрация текстур не поддерживается, доступна только выборка значений без фильтрации
- Поддерживается буфер кадра в плавающем формате (включая операции блендинга в формате компонент FP16 и только запись в формате FP32)
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- 2 × RAMDAC 400 МГц
- Технология NVIDIA PureVideo
- Программируемый видео процессор
- Аппаратное ускорение видео высокой четкости форматов H.264, MPEG-2 и WMV9
- Пространственно-аппаратный деинтерлейсинг для HD видео
- Обратный пересчет кадров 2:2 и 3:2
- Высококачественное масштабирование с использованием фильтра размером 4х5 сэмплов
- Повышение резкости изображения на LCD
- Коррекция цвета оверлеев
- Microsoft Video Mixing Renderer (VMR) поддерживает несколько видео окон с полноценным качеством и возможностями видео в каждом окне
- Интегрированный HDTV выход
Ускорение физики: NVIDIA, ATI и AGEIA
Как мы уже отмечаем на протяжении нескольких месяцев подряд, ускорение физических расчетов средствами графических адаптеров набирает всё большие обороты. Но если еще пару месяцев назад компании-производители графических адаптеров сообщали лишь достаточно общие сведения о своих планах, то теперь уже доступны вполне конкретные решения. Так, забегая чуть-чуть вперед, скажем, что технология CUDA (ранее также известная как Quantum Effects) будет доступна в анонсированных 8 ноября платах на графическом процессоре G80 (GeForce 8800 GTX). Будет поддерживаться ускорение физики в играх, использующих физическое ядро Havok 4.0. Технология будет задействовать отдельные шейдерные процессоры, свободные от задач визуализации, и это дает надежду на то, что для получения реалистичной физической модели можно будет обойтись одним мощным видеоадаптером, не прибегая к SLI, не говоря уж об установке третьей платы в систему.
ATI, пока не давшая адекватного ответа на анонс G80, продвигает альтернативное решение — Stream Computing, что можно перевести, как «потоковые вычисления». Новая технология должна позволить графическим процессорам ATI выделять свои ресурсы для решения задач, требующих дополнительной вычислительной мощности. Первые результаты впечатляют, что неудивительно, если вспомнить, какой объем вычислений выполняют графические ускорители, работая по своему основному предназначению — выполняя визуализацию сцен в трехмерных играх. Согласно данным, опубликованным ATI, обработка моделей, похожих на те, что применяются финансовыми структурами, была выполнена в 16 раз быстрее, чем традиционными средствами, обработка сейсмической модели в интересах нефтегазовых компаний ускорилась в 20 раз, а исследования в области медицины, проводимые в Стэнфордском университете, — в 40 раз, что дало возможность завершить расчеты, на которые требовалось три года, всего за один месяц.
Напомним, в наиболее мощном графическом процессоре ATI находится 48 вычислительных блоков. Безусловно, не все задачи хорошо подходят для решения силами графического процессора. Вот неполный список областей, где, по мнению ATI, можно рассчитывать на максимальную отдачу: научные исследования в сфере здравоохранения и метеорологии; системы безопасности, включая средства распознавания личности и анализ видеозаписей; финансовое прогнозирование; моделирование в интересах нефтегазодобывающих компаний; поиск в базах данных; видеоигры. Одним из примеров применения Stream Computing является проект Folding@home. Этот проект стартовал в 2000 году и направлен на моделирование процессов свертывания/развёртывания молекул белка, дабы получить лучшее понимание причин возникновения болезней, вызываемых дефектными белками, таких как болезнь Альцгеймера, Паркинсона, диабет типа II, коровье бешенство и склероз. К настоящему времени проект Folding@Home успешно смоделировал процесс свёртки белковых молекул на протяжении 5-10 микросекунд — что в тысячи раз больше предыдущих попыток моделирования.
Для выполнения вычислений Folding@Home использует не суперкомпьютер, а вычислительную мощь сотен тысяч персональных компьютеров со всего мира. Для того, чтобы участвовать в проекте человек должен загрузить небольшую программу-клиент. В среднем типичный современный компьютер загружен лишь на 5 %, и клиентская программа Folding@Home запускается в фоновом режиме и выполняет вычисления лишь в то время, когда ресурсы процессора не полностью используются другими приложениями.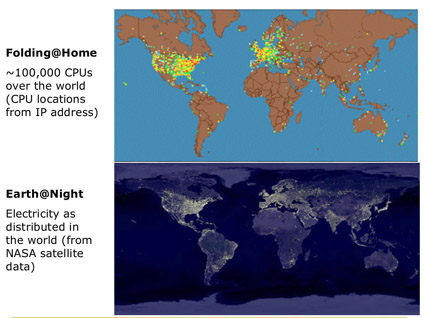
Программа-клиент Folding@Home периодически подключается к серверу для получения очередной порции данных для вычислений. После завершения расчётов их результаты отсылаются обратно. На быстром процессоре расчет 1 секунды реакции свертывания белка занял бы 2700 лет. Сейчас же над задачей трудятся более 100 тысяч компьютеров по всему миру. Напомним, что в планах разработчиков — включить в проект и владельцев игровых приставок PlayStation 3.
Конечно, не собирается спокойно смотреть на то, как NVIDIA и ATI почивают на лаврах созданного ею направления и главный виновник всей этой «физической смуты», компания AGEIA. Её главный козырь — то, что компания уже предоставляет готовые продукты более полугода, в то время как конкуренты только сейчас обеспечили возможность ускорения физрасчетов на видеоадаптерах. Компания не преминула шансов воспользоваться прошедшей в Нью-Йорке выставкой Digital Life для демонстрации возможностей своих продуктов. Среди игр, разработчики которых обеспечили поддержку «ускорителя физики», названы CellFactor, Infernal, Black-out Saigon и Stoked Rider: Alaska Alien. Кроме того, известно, что наличием в конфигурации ПК чипа AGEIA смогут воспользоваться игры Ghost Recon Advanced Warfighter, City of Villains и Bet on Soldier: Blood of Sahara. Примечательно, что для того, чтобы не полагаться на субъективные оценки выигрыша, обеспечиваемого аппаратным ускорителем расчетов, связанных с физическим моделирование, AGEIA подготовила RealityMark — соответствующий тест производительности. Среди демонстрируемых новинок есть и инструмент разработчиков — Dark Physics. Однако изюминкой экспозиции, безусловно, является долгожданной вариант платы PhysX для PCI-Express. Появление этого продукта в продаже ожидается ближе к праздничному сезону, в составе готовых компьютеров.О высоком...
А теперь об обещанных суперкомпьютерах. Помните 80-ядерный процессор Intel, продемонстрированный на недавнем IDF Fall`06? Этот процессор был создан в рамках инициативы Tera-Scale, в рамках которой предполагается в будущем довести производительность микропроцессоров до уровня триллионов операций с плавающей запятой в секунду.
Однако, в этой своеобразной «гонке за количеством ядер» лидирует отнюдь не Intel. Так, созданный новой архитектуре компанией Ambric микропроцессор Am2000 содержит до 360 ядер. Компания называет Am2000 «первыми в мире чипами класса teraOPS» и подчеркивает, что в них используется «глобально асинхронная, локально синхронная» (globally asynchronous, locally synchronous — GALS) архитектура, обеспечивающая решение сложных вычислительных задач с опорой на массовый параллелизм.
Особенностью чипов Ambric является высокая производительность (отсюда и термин teraOPS, указывающий на способность выполнить триллион операций в секунду), а также новаторская, структурная объектно-программная модель, которая «существенно ускоряет разработку и отладку встраиваемых приложений». Предполагается, что на начальном этапе новыми чипами заинтересуются разработчики решений для обработки видео и статичных изображений. Вслед за ними должны последовать потребители, специализирующиеся на приложениях цифровой обработки сигналов, и представители других областей, где сейчас используются программируемые вентильные матрицы (FPGA) и цифровые сигнальные процессоры (DSP).
В чипах Am2000 используется парадигма «много потоков команд, много потоков данных» (multiple-instruction, multiple-data — MIMD), воплощенная в массиве 32-разрядных процессоров с RISC-архитектурой, связанных с распределенной внутрикристальной памятью множеством асинхронных каналов. 
Флагманской моделью серии является микросхема Am2045, состоящая из 360 процессоров и 4,6 Мбит памяти. Ее производительность равна 1,08 teraOPS. Энергопотребление микросхемы составляет 3-14 Вт, в зависимости от нагрузки. Утверждается, что по пропускной способности Am2045 в 10-25 раз превосходит лучшие 90-нм цифровые сигнальные процессоры, работающие на частоте 1 ГГц. Другие варианты Am2000 имеют 280, 192 и 96 процессоров.
Тем временем Sun решила пойти по другому пути. Вместо объявления концепции будущего, компания предложила то, что можно использовать уже сейчас: проект «Черный ящик» (Project Blackbox), в рамках которого предоставляются передвижные вычислительные центры, размещаемые в стандартных транспортных контейнерах.
В состав вычислительного центра входит несколько серверов, хранилища данных, сетевое оборудование и программное обеспечение, а также подсистемы, обеспечивающие питание и охлаждение техники. Предполагается, что разработка, находящаяся в завершающей стадии опытного проектирования, будет идеальным решением для военных. Кроме того, новинкой могут заинтересоваться гражданские потребители, которым необходим мобильный вычислительный центр. Например, это могут быть нефтедобывающие компании, которые с помощью такого центра, установленного на океанской платформе, смогут анализировать данные геологической разведки.
В составе центра Sun Blackbox может быть до 240 серверов Sun Fire, работающих под управлением ОС Solaris 10, что дает суммарную емкость хранилища 1,4 петабайта.
А если уже сейчас можно создавать транспортируемые суперкомпьютеры, то не за горами тот день, когда их будут размещать и на автомобилях и самолетах. Впрочем, в Honeywell смотрят выше и уже думают над тем, как бы разместить суперкомпьютер в космосе. В содружестве с Флоридским университетом (University of Florida) инженеры компании ведут работу над компьютером для космических аппаратов, который, как утверждается, превзойдет по производительности любой компьютер, используемый сейчас в этой области, по меньшей мере, в 100 раз.
Свой первый полет «космический суперкомпьютер» должен будет совершить в рамках тестовой программы NASA в 2009 году на борту беспилотной ракеты ST8. 
Потребность в большой вычислительной мощности объясняется выросшим объемом данных, поступающих от научного оборудования, устанавливаемого на космических аппаратах. Бортовые компьютеры космических кораблей по производительности заметно отстают от бурно развивающейся вычислительной техники на Земле. А все дело в том, что им приходится работать в сложных условиях, и разработчики концентрируют усилия на других характеристиках, в частности, на защите от космического излучения, пагубно влияющего на работоспособность электронной техники. В результате, хотя спутники и пилотируемые аппараты оснащаются все более совершенными датчиками и приборами для сбора информации, большую часть этих данных приходится отправлять в наземные центры для обработки. А здесь есть свои недостатки: ограниченная ширина полосы пропускания каналов связи плюс необходимость умеренного расходования заряда аккумуляторов/солнечных батарей не позволяет отправлять на Землю слишком много данных.
Для решения этой проблемы разработчики решили не защищать компьютер от излучения механически, а компенсировать вредное воздействие на работу процессора и других узлов за счет специального, устойчивого к сбоям, программного обеспечения, способного автоматически диагностировать сбои техники. Разработка получила название Dependable Multiprocessor (можно перевести как «достоверная многопроцессорная система»). Что касается аппаратов, находящихся вдали от Земли, более мощные компьютеры позволили бы им анализировать информацию на месте и принимать решения, не дожидаясь обмена данными и командами с центром управления.
Но вернемся из космоса на землю. В развитых странах технологиями распределенных вычислений уже пользуются довольно многие корпорации. Конечно, отстать от прогресса не хотят и в развивающихся странах — и вот Индия объявила о начале реализации национального проекта распределенных вычислений.
Названный Garuda National Grid Computing Initiative, проект объединит в вычислительную сеть 45 индийских университетов, расположенных в 17 городах. Выполняемый под эгидой индийского Министерства информационных технологий, проект будет поддерживать стандарты IPv4 и IPv6 и, как утверждается, связь между участвующими в проекте университетами будет высокоскоростной.
В проекте создания национальной распределенной вычислительной сети примут участие несколько Индийских Технологических Институтов (Indian Institutes of Technology), Космический Центр Вкирама Сарабхаи в Тируванатапураме (ранее известном как Тивандрум и являющимся административным центром штата Керала) и Институт Исследований плазмы в Ахмедабаде.
Целью проекта является создание материальной базы для исследования технологий, архитектур, стандартов и приложений для распределенных (grid) вычислений. Кроме того, в рамках проекта планируется объединить имеющийся у индийских ученых потенциал для разработки нового поколения сетевых технологий.
В завершение этого раздела — о технологии, с суперкомпьютерами не связанной, но весьма интересной. Когда этой весной ученые университета Duke сообщили о теоретической возможности создания плаща-невидимки, им казалось, что на его создание уйдет не меньше пяти лет. Однако, в октябре состоялась демонстрация работающего прототипа такого плаща (демонстрацию можно посмотреть на видео, формат — Real Video). Правда, прототип пока что способен сделать невидимой лишь небольшую область — всего пять квадратных дюймов (или 32,2 кв. см) и то только от микроволновых лучей. Однако, теоретические идеи, изложенные в начале этого года и нашедшие первое воплощение этой осенью, вполне жизнеспособны и в роли основы для плаща, делающего какой-либо объект невидимым и в видимой области излучения тоже.
Прототип плаща-невидимки создан из метаматериала, способного направлять микроволновое излучение вокруг объекта. Метаматериалом ученые назвали искусственные композиты, взаимодействующие с излучением так, как ни один из известных в природе материалов. В сообщении университета отмечается, что композитный материал содержал серии концентрических окружностей, каждая из которых обладала отличными друг от друга свойствами (способностью взаимодействовать с электромагнитным излучением). Направляя излучение вокруг объекта, метаматериал позволяет снизить как его отражение, так и отбрасываемую тень — и то, и другое снижает его заметность для наблюдателя. Однако, так как в природе невозможно добиться 100% эффективности, очевидно, что небольшая тень, равно как и отражение, все равно присутствует и будет присутствовать и в будущих вариантах метаматериала тоже.
Помимо уникальных свойств материала, есть и еще одна тонкость. Говоря о математике расчетов, исследователи сравнивают помещенный за экран объект с небольшим камнем, лежащем на дне мелкого ручья, или с кончиком иглы, упирающейся в ткань. В первой метафоре вода может течь как вокруг камня, так и поверх его, если позволяют размеры, а во второй — кончик иглы натягивает ткань до тех пор, пока не прорывает её. А это означает, что создать плащ, способный сделать невидимым крупный объект, например, человека, не так-то и просто.
Надо полагать, причиной, по которой ученые пока не смогли сделать «плащ-невидимку» для видимого диапазона излучения, является невозможность (пока) создать метаматериал, содержащий концентрические окружности соответствующих размеров — диаметр таких окружностей, исходя из общих соображений теории дифракции, должен быть меньше диаметров окружностей, использованных для направления микроволнового излучения вокруг крупногабаритных объектов. Однако, ученые планируют работать в этом направлении и в дальнейшем, создать «плащ-невидимку» и для видимого диапазона.